 Paul's Archives
Paul's Archives

K8s 실패 + Docker 환경으로의 전환 정리
제목처럼, K8s 로의 완전한 통합환경 구축의 실패와 이후 Docker 기반의 컨테이닝으로 실서비스 배포에 대한 전체 내용을 정리한 글이다.
증명을 할 필요가 있다
Protostar 프로젝트를 진행하게 된 것은 어디까지나 1년 차인 내가, 참 많은 일들을 겪었고 증명이 이제는 필요하다는 생각을 했다.
개발자로 살아남기 위해선 정말 어려운 일들을 해낼 수 있을 지식의 풀과 넓이가 있어야 하고, 결국 그걸 증명해내야 한다.
반대로 말하면 물경력이 되는 이유는 당연하지만 ‘회사’는 메이는 곳이고, 회사에서 경험을 쌓는 공간으로 개인 입장에서 맞지만, 한 편으로 그것은 회사의 입장과는 상관 없는 입장이며, 회사의 규모와 수준에 맞춰서 기회가 생기는 것이니, 절대 다수가 1류 기업에 들어갈 수 없다는 점을 생각한다면 대다수가 물경력이 되는 이유는 바로 이 지점에서 생긴다고 생각한다.
그러니 나아가서 증명. 기업이 바라는 인재가 되려면 무언갈 해야하지만, 회사에서 그걸 하긴 쉽지 않다. 그리고 동시에 내 개인의 사정 등등… 결국 고려하고 달려온 결과, 증명의 필요가 있었다.
왜 Kubernetes(k8s) 인가?
백엔드 개발자로 사실 백엔드 기술 측면에서 본다면 당연히 프레임워크, 그리고 각종 보안에 대한 이해도가 필요하다. 특히 리소스, 대용량 서비스, 특히나 메시지 기술을 활용한 분산처리는 백엔드의 꽃이자 A to Z 라고 배웠다.
그러나 오케스트레이션 도구인 K8s 의 등장은, Container 기술을 기반으로 성장하고 Docker 로 꽃 피운 새로운 시대에, 더욱이 위의 핵심, 맹점을 제대로 다루기를 가능케 했다.
- Self healing : Desired State 를 기술함으로서, 자동 재시작이 가능해지고, 노드 관리를 통해 컨테이너들을 자동으로 유지 시켜준다.
- Auto Scaling : 1번과 함께, 트래픽에 대한 하드웨어 모니터링, 리소스 기준을 제시해줌으로써 대용량 설계를 손쉽게 가능하게 한다.
- Rolling Update & Rollback : 여러 CICD 파이프라이닝 도구들을 기반으로 무중단 배포(Zero-down time) 의 구현이 손쉽고, 이는 이용자가 모르는 사이에 업데이트 및 서비스 가용성을 극대화 시킨다. 또한 잘못된 업데이트가 이루어질 때 이에 대한 롤백은 명령어 하나로 즉시 가능하다.
- Bin packing : 각 컨테이너의 필요한 자원의 수준을 결정하고, 이에 따라 노드들을 구성, 서비스를 위한 하드웨어에 그 자원을 딱 맞춰 사용할 수 있도록 구축이 가능하므로, 이를 통한 인프라 비용의 최적화를 이루어낼 수 있다.
- Cloud Agnostinc : AWS, GCP, Azure 등 혹은 자체 데이터 센터까지, 사실 최초의 서비스 플랫폼들은 각각 자체적인 기준과 락인 형태를 구축하기 바빴다. 물론 그렇게 구축되는 것이 매우 편리한 것은 사실이며, 또한 안정성 역시 담보 받을 수 있었다. 하지만 문제는 락인 되었을 때 비용, 동시에 환경들이 별도이다 보니 발생하는 버그 발생 가능성, 그리고 서비스 플랫폼을 여러 곳에서 쓴다고 한다면 설령 Containerize 된 환경이라도 발생 가능한 여러 이슈들의 종합적인 대응. 이를 위하여 완전 표준 기술처럼 동작하고, 이를 기반으로 설정되기에 일부 특화 서비스를 제외하곤 클라우드 제공 업체, 환경을 뛰어넘는 배포를 가능케한다.
하지만 이번에는 실패했다 & 아쉽지만 다른 방법으로
그리하여 호기롭게 도전하였다. Dockerize는 너무나 쉬운 일이었고, 이제는 Docker 기반으로 나름대로 뭐든 올릴 수 있겠다는 확신이 있었다. 또한 거기서 내가 뭘 더 할 수 있어야 나에게 도움이 되는가? 라고 한다면 당연히 데이터의 관리 파이프라인 전반에 대한 이해도를 높이는 것이리라 생각했다. 그렇기에 k8s 를 선택. 파고 들어보았다.
순조롭던 MicroK8s 부터 ArgoCD 까지
서버의 배포는 원래 아주 가벼운 OS 기반으로 할까 생각을 했다. Arch 나 Alpine. 하지만 종합적으로 여러가지를 고려한다면 어차피 세팅이 필요한 호스트 OS 이다보니, 이러한 설정이 다 있는 편리한 OS, Ubuntu 기반으로 생각했다.
그러니 당연히 snap 을 기본으로 쓸 수 있었고, Snap의 장점인 완전히 격리된 환경에서 구동 가능한 앱 환경에서 쓰기 편리한 것, 그것이 바로 MicroK8s 라는 도구였다.
MicroK8s 를 설정한 이유는 위에서 언급한 부분도 있지만, 가볍다고 소개가 되어 있었고, 쉬운 확장성 기능들을 지원해 microk8s enable dns 이런식으로 명령어 한줄이면 서비스 구축을 위한 애드온들을 기본 내장하고 있었다. 특히나 CNCF 인증을 받아, 기존에 많이 쓰던 AWS, GCP 등 어떤 곳이든 클라우드 환경과 동일하게 작동을 보장했다.
처음에 살짝 해매긴 했지만(--classic 옵션 넣고 설치해야함), 나름 순차적으로 진행이 되었으며 GitHub 을 기반으로 단일진실공급원(Single Source of Truth, SSOT) ArgoCD 를 통해 확실하게 기반을 다져나갔다.
ArgoCD
# 1. 'argocd'라는 네임스페이스(공간) 생성
sudo microk8s kubectl create namespace argocd
# 2. ArgoCD 공식 설치 YAML 적용
sudo microk8s kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
ArgoCD 접속 가능하도록 임시 설정하기
# A5 서버의 8080 포트를 ArgoCD 서버(argocd-server)의 443 포트로 연결
# 0.0.0.0 추가로 외부에서 접속 가능하게함
sudo microk8s kubectl port-forward --address 0.0.0.0 svc/argocd-server -n argocd 8080:443
ArgoCD 를 기반으로 하게 된 이유는 간단하다. 우선 핵심 인프라의 설정과정에서 국내에서 다소 표준처럼 쓰이고 있다는 사실을 알 수 있었다. 또한 써보면서 알게된 거지만 당연하게도 GitOps에 최적화된 다양한 설정들이 존재했다.
원래 같으면 1) 개발자가 직접 명령어를 쳐서 구현하던가, 2) Jenkins / Github Action 기반의 배포 스크립트를 구축하는게 방법이겠지만 이하 내용 때문에 ArgoCD 를 써야 한다고 확신했다.
- CI 와 CD 의 분리 : Jenkins 로 배포를 만들다보면, CICD 의 의존성, 복잡성이 증가하는 것을 경험할 수 있다. 하지만 ArgoCD 는 CD 부분을 담당하여, 3분마다 동기화를 해주고, 지정된 상태에 따라 기본적인 오케스트레이션을 해주며, 특히 단순하게 특정 어플리케이션만을 위한 형태가 아니라, 각 ‘개별’ 어플리케이션의 상태와 관계 없이 바라보게 해준다. 이러한 점은 (1) Jenkins 가 배포와 관련된 영역에 대한 책임에서 해방되면서, Jenkins 의 관리 영역이 획기적으로 줄어들게 되고, 순수하게 CI에만 집중하면 되게 된다. (2) Jenkins 가 접근을 외부에서 내부로 하게 되다보니 생길 보안의 이슈가 원천적으로 차단되고, ArgoCD 가 직접 Git Repo를 Pull 하는 방식이니, 외부 접속과 관련된 보안 틈을 만들지 않는다. (3) 클러스터로의 통로를 담당하는 키, 환경변수 등 모든 것들이 외부에 있을 필요가 없다. ArgoCD 가 내부에서 쥐고 있다.
- 설정 표류 감지 및 자동 복구 : Jenkins 의 배포를 자동화 하는 경우도 있을 것이고, 수동으로 할 때도 있다. 둘다 문제가 있다. 수동으로 하면 적절하게 진행하기가 안되거나, 관리 인원이 여럿이 되는 순간 꼬일 수 있는 일이 발생한다. 또 자동으로 되어 있다면, 누군가 급하게 무언가 수정했다고 칠 때, 그 내용은 Jenkins 는 알 수 없다. 그리고 그 상황에서 배포가 이루어지면 시스템의 마비를 초래할 수도 있으며, 무엇보다 구성원들의 협업에서 맥락의 단절이 발생한다. 하지만 SSOT(단일 진실 공급원)에 충실한 ArgoCD 기반의 배포는 매우 훌륭하게 이 문제를 해결한다. 모든 것, 즉, 롤백도, 코드의 변경 등 모든 변화의 대응은 Git 의 레포지터리가 담당하고, 그 과정에서 어떤 정책으로 할 지만 잘 결정하면 어떠한 이슈 없이도 대응이 가능하다.
이러한 점들 때문에 project-protostar-k8s-config라는 단일 레포를 만들고, 여기에서 메인 서버와 모니터링 서버 별로 자원 배포 및 서버 구동을 위한 infrastructure 들을 구성해보았다. 특히 여기서 적극 도입해본 것이 Helm Chart 의 패키징 방식이었다.
Helm Chart의 위험성(?)
여기서부터가 문제의 시작점. Helm Chart 는 도커의 이미지에 비하여, 애플리케이션 배포의 실전성을 추가해주는 방식의 도구였다. k8s 에서 애플리케이션을 배포할 때, 특히 실무에서 필요한 여러 설정들이 있고, 특히 failure 를 고려한 이중, 삼중의 시스템 패키징이 되어 있는걸 손쉽게 다운 받을 수 있다- 이 점 때문에 필요하고, 또 실제로 그걸 기반으로 Monitoring 서버 구축, Loki 나 Promtail, Grafana의 설정은 핵심이었기에 룰루랄라 설정을 이어갔다…하지만…
우선 Helm을 운용하는데 문법이 상당히 복잡했다. 뿐만 아니라 가장 핵심은 ‘욕심이 과했다’ 라고 이해하는게 핵심이다. 버전이 어떻게 호환되고, 또 어떤 식으로 써야 할지도 모른체 구축되는 수많은 어플리케이션의 연쇄는 핸들링을 하는 과정에서 제대로 연결이 안되는 온갖 문제들을 야기했다.
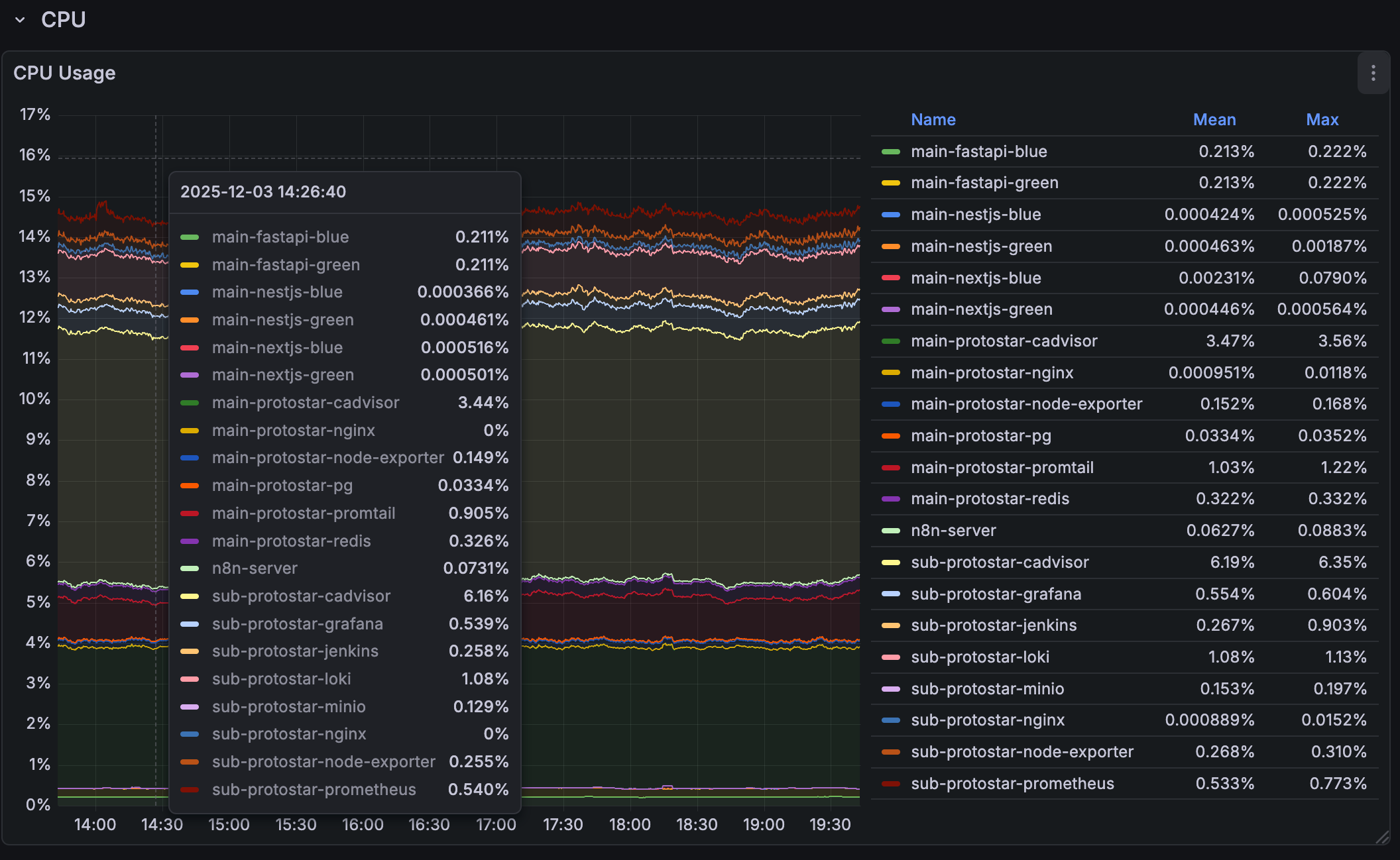
현재 단일 서비스를 위해 올라간 모든 컨테이너(물론 지금은 Docker 로만 되어 있고, k8s 를 걷어내긴 했다.)
그리고 거기서 가장 극심한 것은 역시나 버전 차이 및 호환성 문제. 단순히 어플리케이션 자체만 래핑하는 거였다면 문제가 훨씬 쉬웠을 것이다. 하지만 ArgoCD 기반에, 각종 에러를 대응하기 위해 Helm Chart 패키징한 어플리케이션이란 내가 설정하는 메인 설정이 아니더라도 뒤에서 안전하게 돌아갈 수 있는 설정을을 하게 되어 있고, 그러다보니 유명한 패키지로 열려 있는 것들을 불러오게되면, 이 내부에도 또 버전들이 낮게 설정되어 있거나, 자신들의 테스트한 버전들이 들어 있고, 이걸 래핑한 걸 또 내가 쓰는 입장이니, 호환성 문제는 매우 예민했다.
만났던 여러 문제들을 정리하면 다음과 같은 문제가 있었다.
- Zalando PostgreSQL Operator 와 PgVector 구축 시 이미지 레지스트리 : 과거 사용되던 것들을 찾아서 기재했으나, 알고 봤더니 기존과 다른 위치에서 배포되고 있었음. AI 도 이상한 소리함. 찾아보니 새로운 곳에서 지원을 했고, 더욱 문제는 pgVector 설정은 별도로 해줘야 하는 것이었음.
- Vector 데이터베이스 구축 시 사용될 yaml 내부의 문자열 문법에러 : AI 를 기반으로 반 바이브 + 학습 방식으로 진행함. 그런데 여기서 실제 필요한 문법 형식과 다르게 학습된 AI 는 이상한 소리를 했고, 이것이 문제일 것이란 점을 한참 지나서 파악하게됨(…)
- 꼬인 리소스 기준으로 좀비 리소스가 된 상태에서의 해결 안됨 : k8s API의 통제권을 ArgoCD 에게 위임하고, finalizer 역시 ArgoCD 로 지정했음. 그러나 여기서 호환성 문제, 특히 Grafana 스택에서 loki 가 있었는데, 문제는 모니터링 서버에 별도로 Grfana를 설치하면서 k8s 의 Grafana 공식 스택과 별도였는데, 이때 Docker 버전 차이, Grafana 버전 차이에 따라 loki의 문법을 제대로 못찾으면서 호환성 이슈가 생김 알게됨. 커넥션 불량이 발생하면 finalizer는 멈추고, 좀비처럼 변해서 ArgoCD 의 통제 명령에 제대로 동작하지 않음. 그 밖에도 MinIO 설정이 필요한 Loki 내부 설정에서의 문제점(최신버전 과 구버전 사이) 등 여러 이슈가 동시 다발로 묶여서 발생함.
- Ingress Nginx 대신 Gateway API 사용 실패 : 지금은 조금더 이해하긴 했지만, 최근 Ingress Nginx 라는 매우 쉽고 편리한 방식에서 API Gateway 를 사용해야 하고 Nginx Fabric 이라는 걸 도입해보려 했으나 에러 발생.
- Snap 기반의 문제: 사용하기 편리하고, 경량이며, 격리된 특성을 가진 snap을 처음 쓸때는 대단히 ‘개발자 친화적’인 도구라고 생각했다. 하지만 여러 문제를 가진 다는 것을 알게 되었을 때는 실제 환경에선 이걸 잘 못쓰면 안된는구나라는 판단이 섰다.
- 우선 가장 문제로
--classic모드로 설정하지 않으면 설치 되더라도 일반적인 호스트 시스템에 접근이 불가능하다. - 또한 Snap 특성상 자동 업데이트를 강제하는데, 이게 개인용 도구라면야 업데이트를 하는게 큰 문제는 아닐 수 있지만, MicroK8s 를 사용하게 되면 이건 심각한 문제가 될 수 밖에 없다고 느꼈다. (물론 이 문제는 오래된 거라, 요즘은 대안이 있지만 ‘번거롭다’는게 흠.)
- 그 밖에도 여러모로 번거로운 부분들이 있었고, 결론적으로 실제 상용으로 쓸 때 MicroK8s 기반이 되는 것 자체는 괜찮았지만, snap 을 쓰는건 절대 하지 말아야겠단 생각이 더욱 명확해질 수 있었다. 개발로 구축한 이후의 서비스에 Snap의 궁합은 대단히 조심스러워야 할 것이었다.
- 우선 가장 문제로
그리하여 얻은 결론은 확실한 검증, 그리고 동시에 확실한 호환되는 툴들을 버전별로 꿰고 있어야 하며, 더욱이 패키지 방식으로 묶인 걸 먼저 쓰는게 아닌 스스로 설정해보는 것을 써보거나, 아예 해당 패키징 된 것을 쓸 거라면 완전히 그것의 의존성에 기대어 개별적인 환경이나, 내 커스텀한 상황으로 만들면 안된다는 사실(…) 이해할 수 있었다.
현재는 K8S 의 기본적인 골조와 구성부터 다시 학습을 하고 있으며, 프로젝트의 진행 그리고 구현할 것들을 감안했을 때는 멈출 수 없다는 전제 하에, 기존의 Jenkins + Nginx + Docker + GitHub 기반의 무중단 배포 방식으로 설정을 진행하였다.
향후 계획
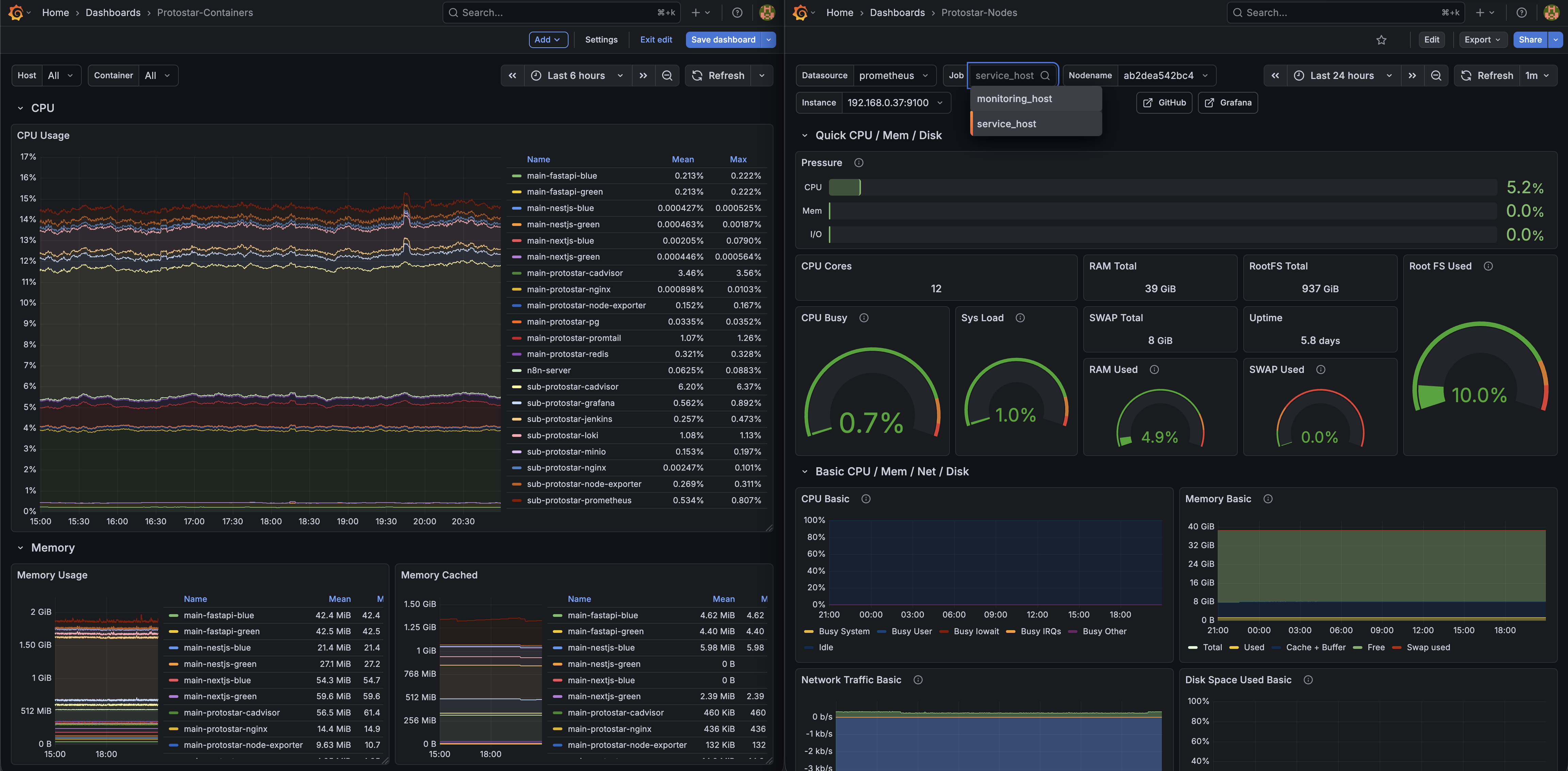
그리하여 돌고 돌았지만 깨달은 점은
- k8s 는 생각 이상으로 별게 맞았다.(?) k8s 자체를 이해하는건 이번 일로 깨달았지만, 문제는 사실 그 안에 채우는 것들이었다.
- 기본기를 배울 좋은 기회였고, 대규모 분산처리를 위해 하긴 할건데, 일단 만드려는 것부터 먼저하자(?)
- Docker 는 진짜 직관적인 것이었다.
와 같았다. 그러나
목표를 위한 키워드 안에 다른 핵심들도 있었기에, 시간 낭비를 줄이고자 바로 노선을 변경. Docker 기반으로 컨테이너라이징 하는 것으로 수정하였으며, 패키지 방식은 좀더 연구를 통해 구성해보려고 한다. 물론, 가장 문제시 되는 호환성은 각 도구 별로 사용법 그 이상으로 이해도를 높이는 시간을 가지면 아마 무리없었지 않을까 싶긴 하다. 그러나, 어쨌든 당장은 목표를 위해 가야 하니 수정… 지금은 다음과 같은 구조로 설정하였다.
Main 서버
- nginx
- exporter
- cAdvisor
- promtail
- Front-end Server(Green, Blue)
- NextJS
- Back-end Server(Green, Blue)
- NestJS
- FastAPI
- PostgreSQL Vector (DB, RAG)
- Redis (Que, Messaging)
Sub 서버
- nginx
- exporter
- cAdvisor
- prometheus
- Grafana
- Loki
- MinIO(Obj Storage)
또한 이를 위한 관리 구조는 다음 레포지터리로 구성했다.
- project-protostar-server-configs : monitoring 핵심 도구레포지터리, Nginx 등의 설정을 관리하는 SSOT로 보장
- project-mini-frontend : NextJS app 및 Jenkins 파일 관리 레포
- project-protostar-nest : NestJS, 서비스 기능 구현 서버
- project-protostar-fastapi : FastAPI 기반 AI 서비스 기능 구현 서버
또한 특징적으로 이러한 문제도 있었는데 KT 회선 하나 당 공인 IP 하나가 할당된다. 따라서 정식 서비스를 온프레미스로 진행시 종단간 암호화를 위해선 HTTPS 443 의 적절한 포트를 할당 해야했다.
그러나 여기서 문제는 Nginx 를 통해 443 포트를 점유하는 것까진 괜찮지만, 문제는 이 경우 어드민으로 관리하는 영역을 접속하는 것도 443 으로 암호화 및 외부 접속 가능하게 만들려면 메인 서버의 Nginx 를 경유하던지 해야 하는게 기본적인 해결책이었다. 그러나 이 경우 관리하는 도구들이 있는 서브 서버는 살아 있고, 메인 서버가 죽어버리는 일등이 발생할 때 문제가 심각해진다.
왜냐하면 443으로 메인 서버의 nginx 를 경유한 순간부터, 서버의 문제 발생 시 이에 대한 적절한 대응이 불가능한 것이다.
이에 L4(Transport Layer) 레벨의 프록시 패스, 앞 단에 무료 GCP 서버를 하나 추가한 뒤, 이를 공인 IP의 다른 포트로 전달. 단 이때 암호화된 패킷을 그대로 전달하기 때문에 암호화는 유지되면서도 하나의 공인 IP 기준으로 443 HTTPS 를 두 선으로 만드는 방법을 적용하여, 관리 회선과 서비스 회선의 분리를 만들어냈다. 그림으로 정리하면 이런 구조다
# 서비스 접속
서비스 접속(443) -> HTTPS -> 공인 IP(443) -> 메인 서버 (443)
# 관리
관리 도구 접속(443) -> GCP 가상 머신(443) -> L4 proxy pass -> 공인 IP (다른 포트) -> 포트 포워딩 -> 서브 서버(443)
다행이 L4 레이어는 암호화를 해지하지 않는다. 단 외부 IP 를 정확히 인지하지 못하게 되고, GCP 가상 머신의 공개 IP 로 기록이 남는 문제는 있다. 이에 Nginx 에서 이러한 문제를 해결하기 위한 옵션을 켜는 것으로 관리 회선과 서비스 회선의 독립을 만들어냈다.
바이브, AI, K8s, DevOps 그리고 Protostar
현재는 데모만 올라가 있다… 계속 개발중
현재 Protostar 서비스는 계속 작업 중이다. 산넘어 산이라더니 K8s 를 적용하는 과정, MSA 폴리글랏 구조, 그리고 거기에 3년차 정도가 해야 하는 많은 도구들. 처음엔 별거 아니겠지(?) 란 생각, 그리고 AI 라는 강력한 도구로 할 수 있을 것 같았지만 이는 오만한 생각이었고, 화들짝 놀라며 방법을 수정. 지금에 이르렀다(…)
물론, 이젠 생각을 달리 하기로 했다. 서비스와 프로젝트의 구체적인 구성을 채우고, 이미지가 준비만 된다면 Git Ops로 옮기는 건 일도 아니었고, 다행이 시행착오 덕에 ArgoCD 기반으로 배포하는 것은 문제가 아님을 파악했고, 오히려 다른 도구들 S3 호환 MinIO 의 관리나, 기타 다른 도구들에 대한 이해도가 더 끌어올라와야 k8s 로 포팅도 쉽게 가능할 것이란 확신을 얻었다. 그러니 달리고 난 뒤에 다시 적용해보겠다. 달리자(…)
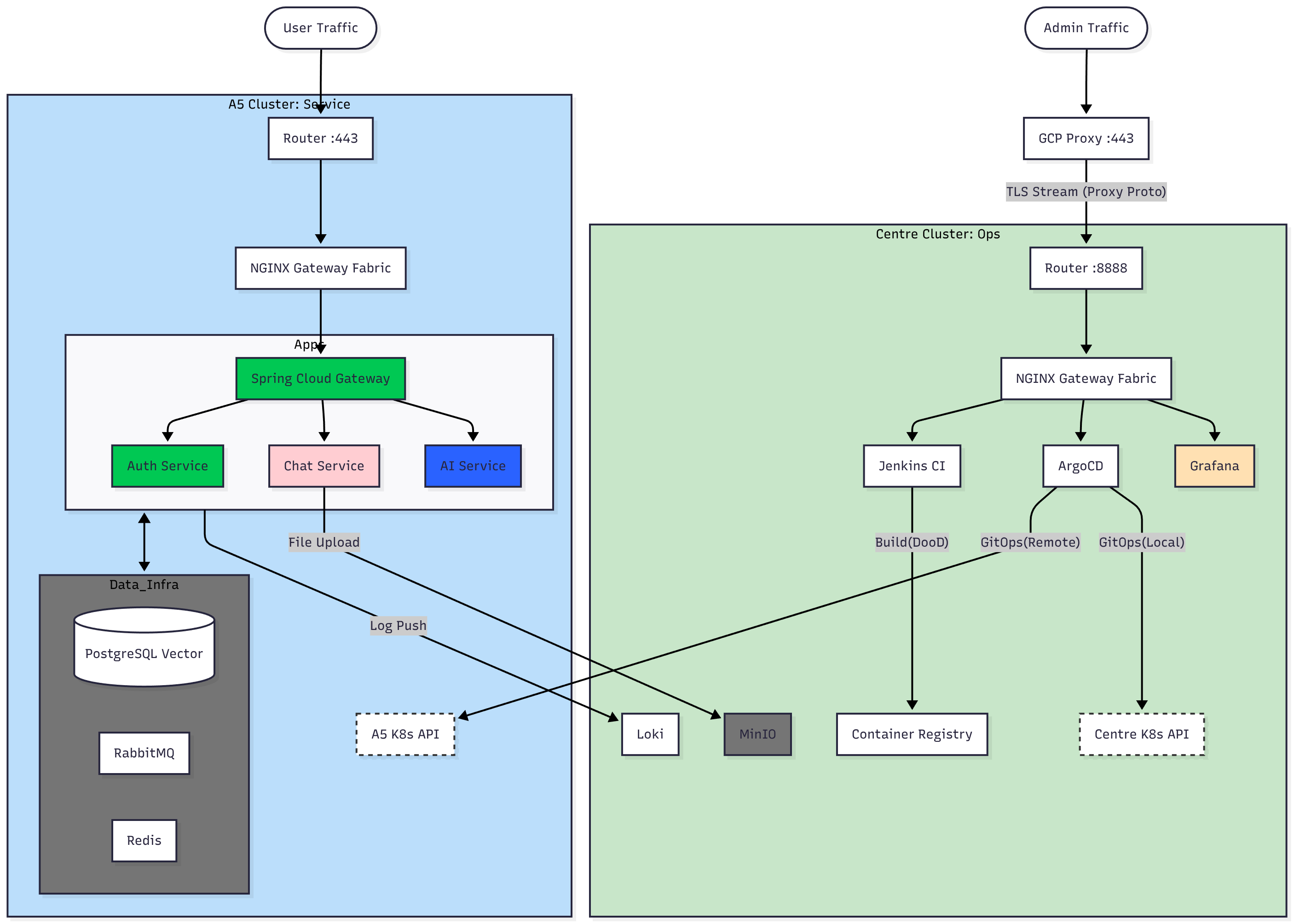
우선 K8s 와 Message 큐 기능은 제외되었다. 향후 추가 예정…