 Paul's Archives
Paul's Archives

Chapter 1 Traffic Dam 구현기 summary
SRE 기반의 유량 제어 시스템을 품은 풀스택 AI 챗봇 구현을 진행했다. Protostar 의 Prototype 에 해당하는 것 + 이에 필요한 트래픽제어기를 구현했던 내용을 기록화 시켰다.
1. 핵심 성과
한 줄 요약
개인 프로젝트 Protostar 의 개발 중 온프레미스 서버에 CVE-2025-55182 취약점을 악용한 공격으로 CPU 자원 포화(Resource Hijacking, 800%) 발생 및 전체 서비스 불능 상태 경험
시스템 보호를 위한 Traffic Dam 에 대한 필요성, 서비스를 위한 적정 용량 산정(Capacity Planning) 의 필요성 절감
검증을 위한 풀스택 AI 챗봇 구현 및 VU 1000 에서 에러율 0% 달성 및 예측 가능한 스케일 아웃의 기준 공식 도출
| 카테고리 | Before | After |
|---|---|---|
| 안정성 | Rate Limiter 없음, 공격 시 전체 시스템 다운 혹은 느려짐 | 1,000 VU에서 에러율 0% |
| 확장성 | 단일 인스턴스 600 VU 한계 | 스케일 아웃으로 1,000 VU 안정 처리 |
| 운영 예측성 | 용량 산정 기준 없음 | 실제 용량 = 기준 × N × 0.83 공식 도출 |
핵심 수치
- 온프레미스 핵심 비즈니스 로직 단일 인스턴스 조합에서의 트래픽 최적의 스윗 스팟 측정 : VU 600 기준
- 서버 리소스를 고려한 스케일 아웃 2배 진행
- 동시 사용자: 600 → 1,000 (67% 증가)
- p95 레이턴시: 2.79초 (목표 3초 이내 달성)
- 스케일 아웃 효율 구체화: 83% (선형 대비)
블로그 상에 구현되 챗봇 데모
서비스를 위한 데모 프론트엔드 페이지
2. 문제 → 해결 → 인사이트
Why: 문제 정의
개인 프로젝트 개발 도중 React Shell 취약점(CVE-2025-55182)으로 L7 공격을 받았다. 인프라를 구축만 하고 프론트 데모만 있었기에 Rate Limiter가 없었다. 무한 요청이 그대로 Next.js 서버로 들어왔고, 전체 시스템은 리소스 부족으로 시스템이 무너졌다. 처음으로 서버의 과부하를 경험하였다. 프론트엔드 취약점이었지만, 피해는 백엔드와 인프라까지 영향을 주었다.
그렇기에 질문이 생겼다.
“취약점은 언제든 발생할 수 있다. 그때 시스템은 어떻게 버텨야 하는가?”
“트래픽의 대응을 위한 스케일 아웃을 어떻게 해야 하는가?”
“구현한 서비스가 데모이든 무엇이든 최적의 성능을 제공해주는 기준이 필요하다”
What: 해결 목표
Protostar 서비스 구현 도중 일어난 사건들, 백엔드 개발자로서 제대로된 서비스를 구현하기 위해선 반드시 이 작업이 필요하다고 느꼈다.
핵심 가설을 세웠다.
“초당 5,000개의 악의적 요청이 들어와도, 백엔드는 초당 100개만 처리하며 죽지 않을 수 있을까?”
이를 검증하기 위해 Traffic Dam을 설계했다. 댐이 물을 막고 조절하듯, 트래픽을 받아내고 제어하는 시스템을 구축하는 것을 목표로 삼았다.
How: 설계 및 구현
아키텍처
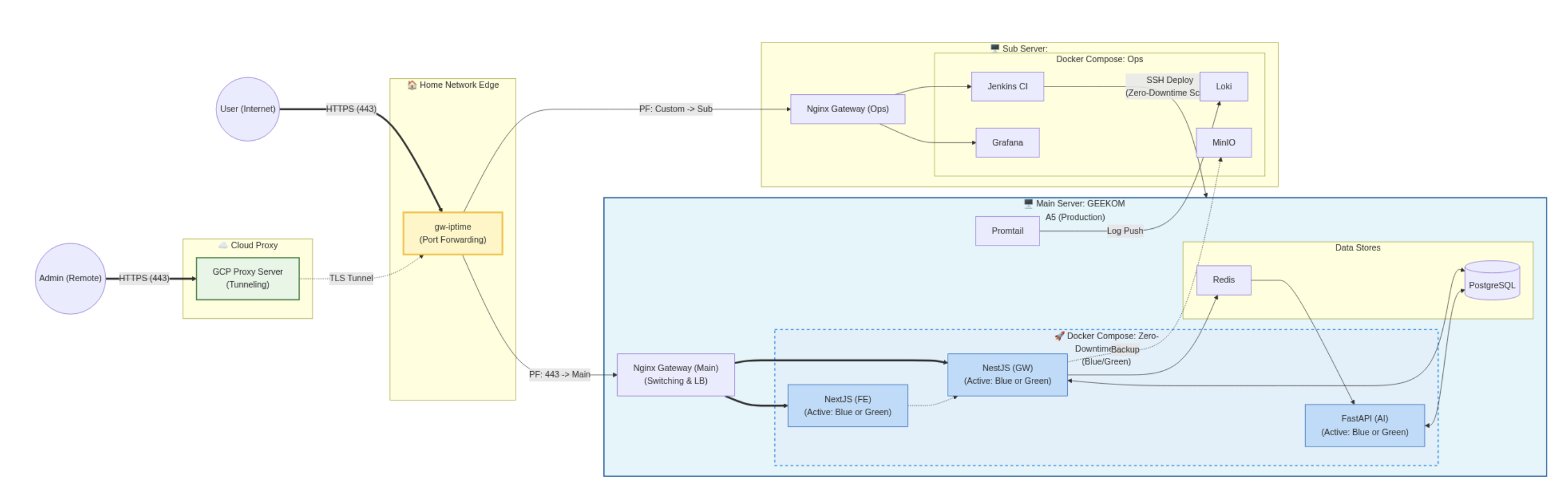
서비스 아키텍쳐, 온프레미스 제약을 해결하는데 시간이 걸렸다
기존 설계와 인프라, 모니터링 구축이 끝난 직후였다. 구현의 목표는 풀스택 AI Chatbot 의 데모를 구현 + Traffic Dam 을 설계하여 목표에 답을 하는 것이다.
- Gateway Layer (NestJS): 대규모 연결 유지, 1차 트래픽 방어, SSE 기반 실시간 스트리밍
- Buffering Layer (Redis/BullMQ): 트래픽 임시 저장, Token Bucket Rate Limiting, Backpressure 대응 도구
- Processing Layer (FastAPI): LLM 처리, OpenRouter API 연동, 고정 처리량 제어
핵심 구현 사항
| 영역 | 구현 내용 |
|---|---|
| 실시간 통신 | SSE 기반 채팅 스트리밍, Redis List 기반으로 멀티 인스턴스 간 메시지 동기화 |
| 트래픽 제어 | Nginx 의 Sliding Window Rate Limiting, Token Bucket Rate Limiting, Max Concurrent Connection(1,000), Job Deduplication |
| 장애 대응 | Circuit Breaker 패턴 |
| Observability | cAdvisor, node-exporter, Winston + Loki 통합, JSON 구조화 로깅, 레이어별 에러 추적, Grafana 모니터링 시스템, Discord 기반 Alert 체계 |
| 인프라 | Docker Compose 기반 스케일 아웃, Nginx 로드밸런싱, Jenkins CI/CD(Zero-Downtime, G/B 전략) |
| AI 서비스 | OpenRouter 기반 LLM 연동, Protostar 프론트엔드 데모 구현 |
개발 방식: AI-Assisted Development
- 초기에는 Antigravity + Gemini 조합으로 개발 및 배포 전 CodeRabbit AI 를 활용한 검토 파이프라인 구축. Obsidian 은 단순 지식 저장용
- 중반부터 Obsidian + Claude Code 체제를 추가 도입.
개선 이유?:
- 생산성 증대: 코드 작성과 문서화를 하나의 흐름에서 처리가 가능하며, AI와 함께 공유가 가능함.
- 데이터 해석력 확보: k6 테스트 결과 분석, 병목 원인 추론에서 Claude의 정확도가 높았고, 이를 체계적으로 파이프라이닝이 필요, CMD + C / CMD + V 는 너무 비효율적임.
- 설계 검증: 내 관점의 설계안에 대해 헛점, 사이드 이펙트, 엣지 케이스를 함께 검토
AI를 단순하게 “코드 생성기“로 보면 안된다고 판단하였다. “빠른 도입 가속기”로 활용했다. 내가 방향을 잡고, AI를 통해 허점을 지적하도록 하여 새로운 기술에 대한 적응력을 높이고, 아키텍쳐의 기술 선택에서 가능한 최적의 선택을 도모하도록 했다.
Result: 검증 결과
k6 기반 부하 테스트로 검증. 온프레미스 서버에서의 최대 트래픽 수치를 구체화 하였다.
| 구성 | VU | 에러율 | Latency(p95) | AI TTFT(p95) | RPS |
|---|---|---|---|---|---|
| 단일(NestJS 1 + FastAPI 2) | 500 | 0% | 710ms | 849ms | 173.18/s |
| 2배 (NestJS 2 + FastAPI 4) | 1,000 | 0% | 2.79s | 3084ms | 287.77/s |
- VU 1,100 이상에서 429 에러가 발생하기 시작했고, 이는 Rate Limiter가 의도대로 작동하여 시스템을 보호하도록 구현 완료
- 전체 시스템은 스케일 아웃이 되었으나, Redis 는 단일 인스턴스로 병목이 발생했음. 이에 메시지 처리 과정의 I/O 경합이 AI TTFT 의 지연의 주 원인으로 분석됨(Latency Trade-off)
Insight: 배운 것
- 스케일 아웃은 선형이 아니다: 2배 확장에 83% 효율. Nginx 로드밸런싱 불균형, 공유 자원 경합, 네트워크 오버헤드가 원인이었다.
- Baseline 설정과 Capacity 에 대한 구체화: 단일 코어당 핵심 로직을 거쳐 NestJS, Redis, FastAPI 로 작업을 처리 시 얼마나 걸리는 지를 파악할 수 있었고, 기록을 기반으로 실제_용량 = 기준_용량 × N × 0.83 라는 수식을 도출. 스케일 아웃 시 얼마나 트래픽을 처리할 수있을지 예상치를 설정하고, 기준을 보다 명료하게 만드는 것에 성공하였다.
- 설계적 Stateless ≠ 집합체적 Stateless: In-memory Session, Redis 공유 카운터 등 암묵적 상태 의존성이 존재했고, Sticky Session 전략이 필요했다. 구조에 대한 이해도가 얼마나 중요한지 느낄 수 있었다.
- 동일 에러 코드, 다른 원인: 같은 429라도 Nginx L7에서 발생한 것과 Application에서 발생한 것은 달랐다. Observability 없이는 디버깅이 불가능했기에 모니터링의 필요성, 로깅의 디테일의 중요성을 느꼈다.
- AI는 도구다: AI 는 복잡한 시스템의 상호작용과 DevOps 의 미세한 맥락을 이해하지 못했다. 이에, 방향(Why & What)의 결정자는 나이자, 제안자는 AI 라는 형태로 설정하였다. 구현(How)은 AI 와 함께 진행하였다. 이때 ‘나’는 공식 문서와, 각 기술들의 최신 맥락을 교차검증하였으며, AI를 일종의 ‘기술 제안자’ 이자 ‘빠른 프로토타이퍼’로 세워 ‘망설이는 시간’을 획기적으로 줄일 수 있었다. 이를 통해 1인 개발의 한계를 넘는 복잡도를 이해하고, 풀스택 서비스 구현과 검증까지 진행 가능하였다.
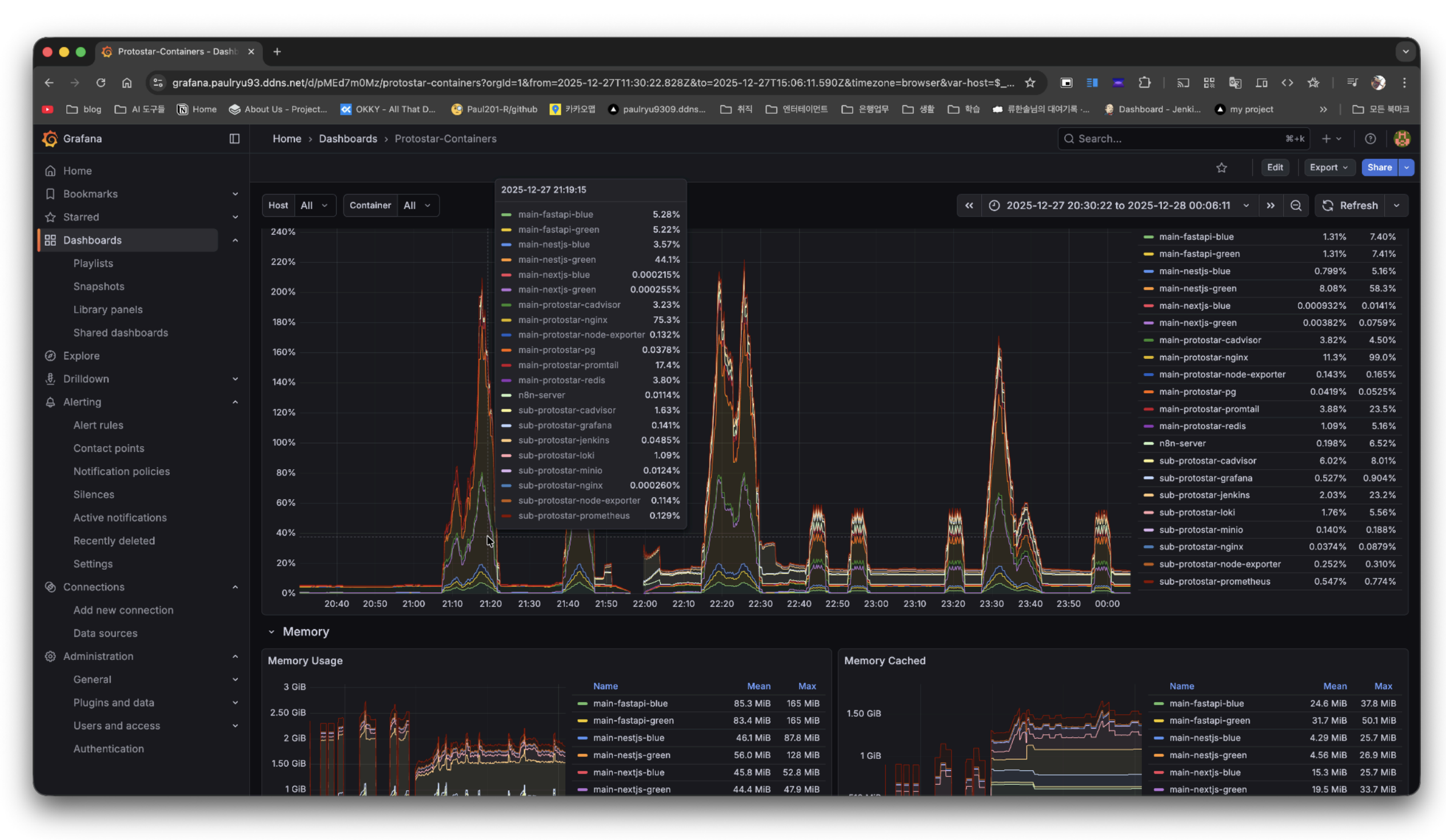
Grafana - Before 테스트 당시 컨테이너 상태
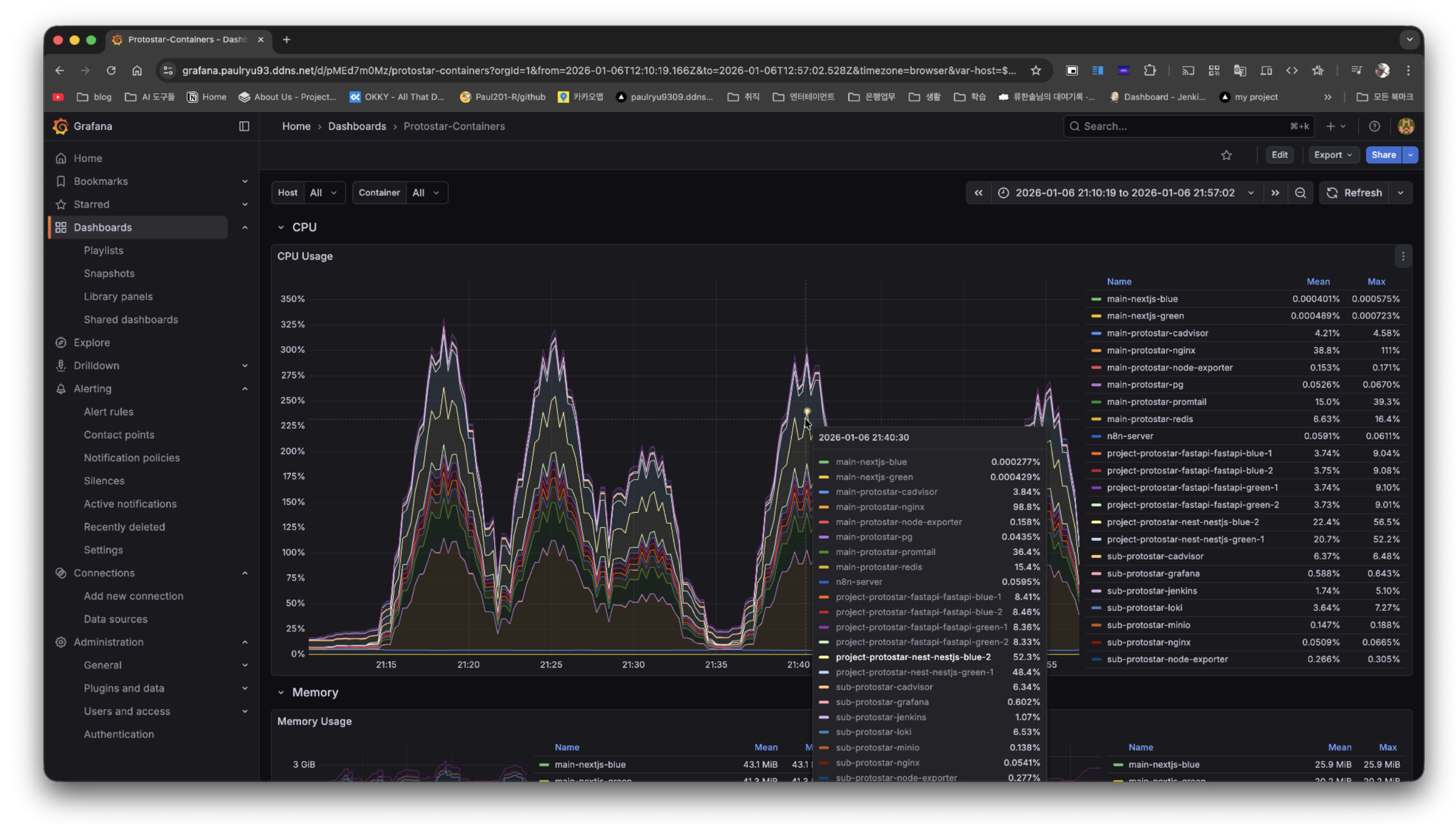
Grafana - After 테스트 당시 두배 스케일 아웃 된 서버들이 병렬로 대응함
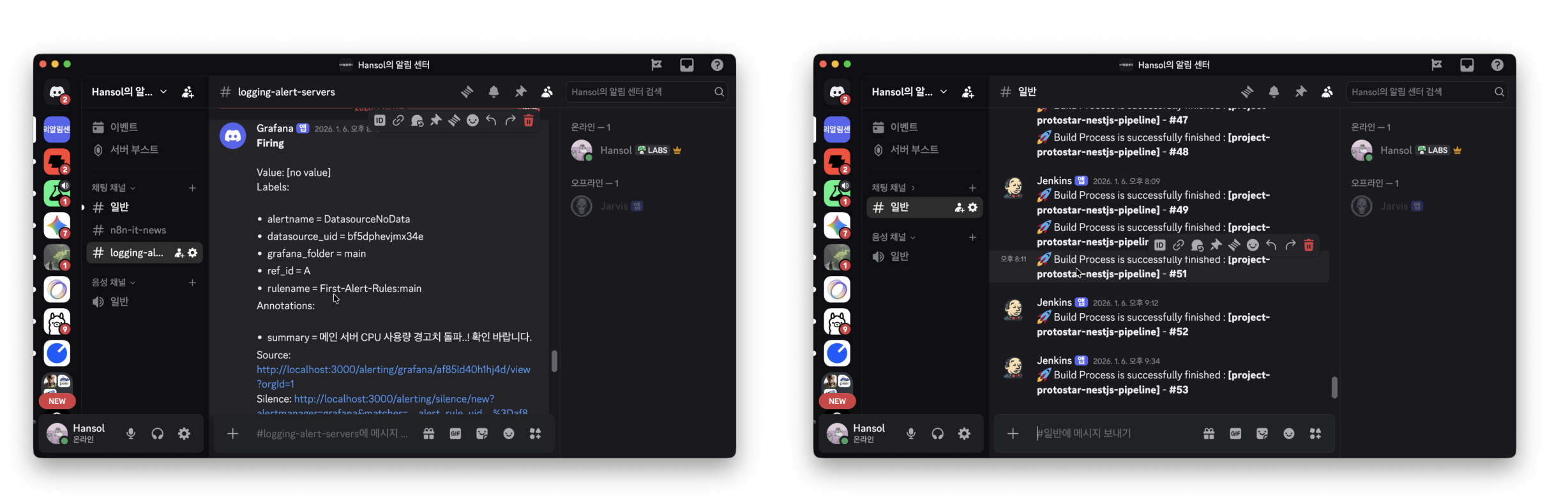
Discord Grafana Alert 와 무중단 배포 알림
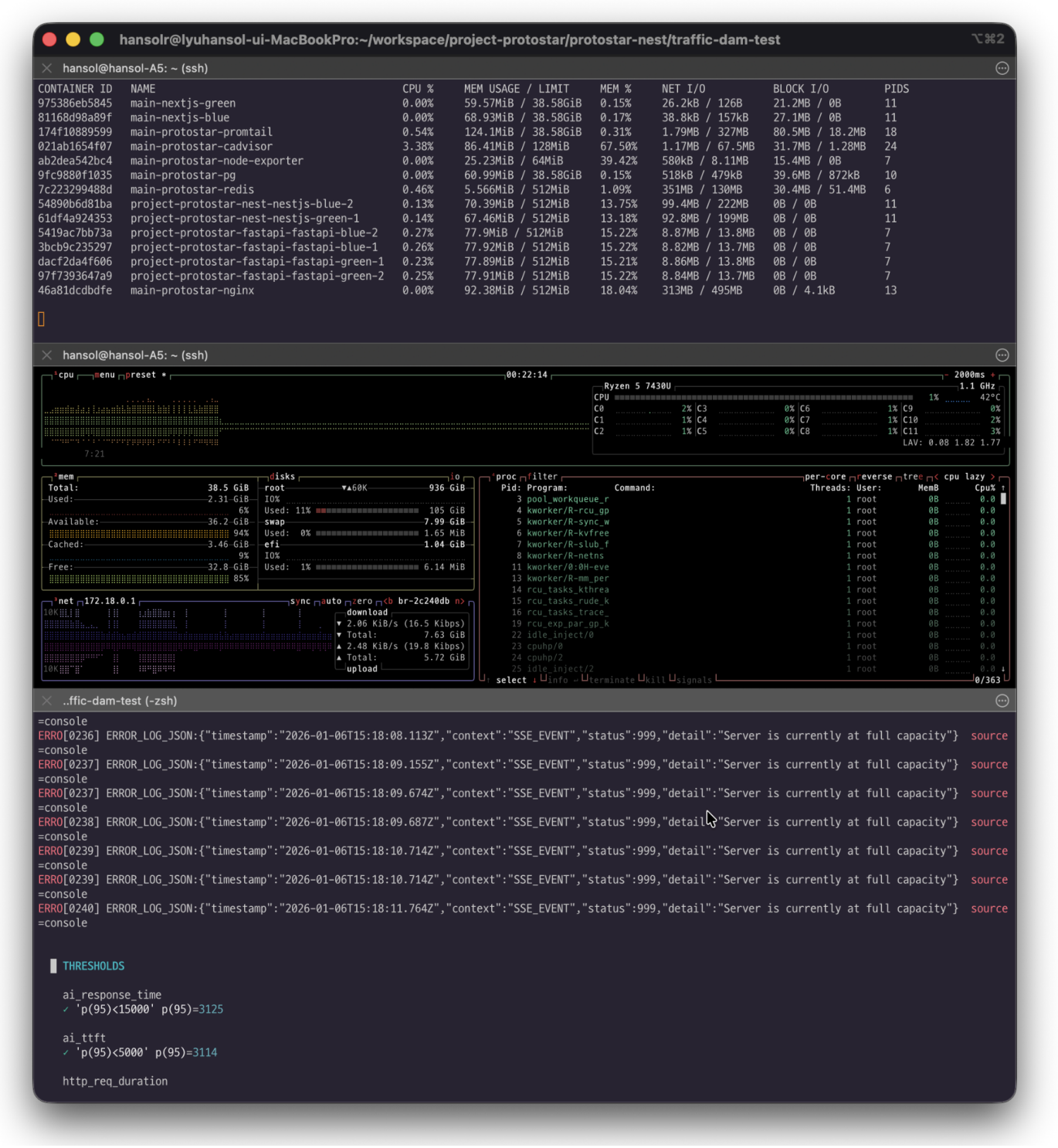
실제 테스트 당시 모니터링 docker stats + btop + k6 화면
3. 마무리
이번 프로젝트를 통해 백엔드 개발자로서 증명해야 할 것이 명확해졌다. 트래픽을 처리할 수 있다면 처리하고, 처리할 수 없다면 시스템은 생존해야 한다. 대용량의 경험을 언제 해볼 수 있을까? 싶지만, 우선 대용량이 아니더라도 서버의 특성에 맞춰 적절하게 대응하는 방법을 배울 수 있던것 같으니… 이걸 기반으로 기회가 올 수 있지 않나 싶다.
Traffic Dam은 그 첫 번째 구현이었고, 용량 산정 공식 도출까지 도달한 점은 의미 있는 성과였다. AI 기반으로 할 때 이런 점에서 좋다고 느낀다. 각 요소에 대한 의미를 놓치지 않게 이야기 하다보면 데이터의 특징이 보인다.
다음 단계로는 DB 최적화, RAG 파이프라인, 프롬프트 엔지니어링 등 AI 서비스의 응용 레이어를 보강할 계획이다. Protostar의 완전체는 구현하기 어려울 것 같지만, 핵심 비즈니스 로직은 내 블로그를 통해 보여지고 실제로 쓸 수 있도록 만들어봐야지.