Paul's Archives
Paul's Archives
introduction
CS 관련하여 부족한 부분들이 조금 있다고 생각했다. 기술 면접을 준비하기 위해, 특히나 백엔드 특화 내용을 확실하게 정리하기 위해 하루에 30분 정도만 소비하기로 했다. 오전 첫 시작 시간을 위한 거라고 보면 될 듯 싶다.
외우는 것까지 되면 좋겠지만… 안되면 일단 기록이라도 제대로 해둬야 하니…
기본 내용은 꽤 괜찮은 글의 내용이 있어 여기를 참고하고, 추가적으로 찾아 다니며 정리한 내용들을 기재하려고 한다.
프로그래밍 공통
OOP란
현실 세계의 구조, 동작, 추상적 개념을 프로그래밍에 옮겨와 특징과 기능으로 구현해내는 프로그래밍 기법으로, 코드 작성시 재 사용성, 변형 가능성 등을 높이는 특징을 가진다.
OOP 5가지 설계 원칙
- SRP(Single Responsibility Principle, 단일 책임 원칙): 클래스는 단 하나의 목적을 가져야 하며, 클래스를 변경하는 이유는 단 하나의 이유여야 한다.
- OCP(Open-Closed Principle, 개방 폐쇠 원칙): 클래스는 확장에는 열려 있고, 변경에는 닫혀 있어야 한다.
- LSP(Liskov Substitution Principle, 리스코프 치환 원칙): 상위 타입의 객체를 하위 타입으로 바꾸어도 프로그램은 일관되게 동작해야 한다.
- ISP(Interface Segregation Principle, 인터페이스 분리 원칙): 클라이언트는 이용하지 않는 메소드에 의존하지 않도록 인터페이스를 분리해야 한다.
- DIP(Dependency Inversion Principle, 의존 역전 법칙): 클라이언트는 추상화(인터페이스)에 의존해야 하며, 구체화(구현된 클래스)에 의존해선 안된다.
절차 지향 프로그래밍 vs 객체 지향 프로그래밍
- 절차 지향
- 순차 처리 중시
- C 언어와 같은 언어가 대표적
- 컴퓨터의 바이너리 처리와 유사하므로, 실행속도가 빠름
- 코드 순서 변경 = 결과 바뀔 가능성 있음
- 객체 지향
- 실 세계를 객체화
- C++, Java, Python 등
- 캡슐화, 상속, 다형성 기법 등으로 보다 추상화된 형태
- 절차 지향보단 당연히 느릴 수 있음
REST API 와 RESTful API
- REST 는 HTTP를 활용한 아키텍처 스타일이고, REST API 는 이를 기반한 API 이다. RESTful API 라고 함은, REST 의 원칙, 제약조건을 최대한 잘 따르며 설계한 API 를 의미, 즉 REST 는 개념 및 원칙이고 ful 이 붙으면 이를 구현한 결과물이라 볼 수 있다.
- REST 는 REpresentational State Transfer 의 약자로, 네트워크 상태가 전이되는 표현을 의미한다.
- REST 원칙
-
클라이언트-서버 디커플링. REST API 디자인에서 클라이언트와 서버 애플리케이션은 서로 간에 완전히 독립적이어야 한다. 클라이언트 애플리케이션이 알아야 하는 유일한 정보는 요청된 리소스의 URI이며, 이는 다른 방법으로 서버 애플리케이션과 상호작용할 수 없다. 이와 유사하게, 서버 애플리케이션은 HTTP를 통해 요청된 데이터에 전달하는 것 말고는 클라이언트 애플리케이션을 수정하지 않아야 한다.
-
Stateless. REST API는 stateless이다. 이는 각 요청에서 이의 처리에 필요한 모든 정보를 포함해야 함을 의미한다. 즉, REST API는 서버측 세션을 필요로 하지 않는다. 서버 애플리케이션은 클라이언트 요청과 관련된 데이터를 저장할 수 없다.
-
캐싱 가능성. 가능하면 리소스를 클라이언트 또는 서버측에서 캐싱할 수 있어야 한다. 또한 서버 응답에는 전달된 리소스에 대해 캐싱이 허용되는지 여부에 대한 정보도 포함되어야 한다. 이의 목적은 서버측의 확장성 증가와 함께 클라이언트측의 성능 향상을 동시에 얻는 것이다.
-
계층 구조 아키텍처. REST API에서는 호출과 응답이 서로 다른 계층을 통과한다. 경험에 따르면 클라이언트와 서버 애플리케이션이 서로 간에 직접 연결된다고 가정하지 않는 것이 좋다. 통신 루프에는 다수의 서로 다른 중개자가 있을 수 있다. REST API는 엔드 애플리케이션 또는 중개자와 통신하는지 여부를 클라이언트나 서버가 알 수 없도록 설계되어야 한다.
-
코드 온디맨드(옵션). REST API는 일반적으로 정적 리소스를 전송하지만, 특정한 경우에는 응답에 실행 코드(예: Java 애플릿)를 포함할 수도 있다. 이 경우에 코드는 요청 시에만 실행되어야 한다.
-
균일한 인터페이스. 요청이 어디에서 오는지와 무관하게, 동일한 리소스에 대한 모든 API 요청은 동일하게 보여야 한다. REST API는 사용자의 이름이나 이메일 주소 등의 동일한 데이터 조각이 오직 하나의 URI(Uniform Resource Identifier)에 속함을 보장해야 한다. 리소스가 너무 클 필요는 없지만, 이는 클라이언트가 필요로 하는 모든 정보를 포함해야 한다.
-
- REST 구성요소
-
자원(Resource) by URI : REST API 는 URI 를 통해 사용할 자원을 명시한다. 보통은 이떄 URI 에 명시되는 자원은 PK 와 같은 고유한 ID 값이다.
-
행위(Verb) by HTTP Method : REST API 는 HTTP Method (GET, POST, PUT, DELETE 등) 를 사용하여 URI 에 명시된 자원에 대해 어떠한 행위를 수행할 것인지를 명시한다.
-
표현(Representation of Resource) : REST API 에서 리소스는 다양한 형태(JSON, XML, TEXT, RSS 등)로 표현될 수 있다. 보통은 JSON 또는 XML 을 통해 데이터를 주고받는 것이 일반적이다.
-
메모리 구조
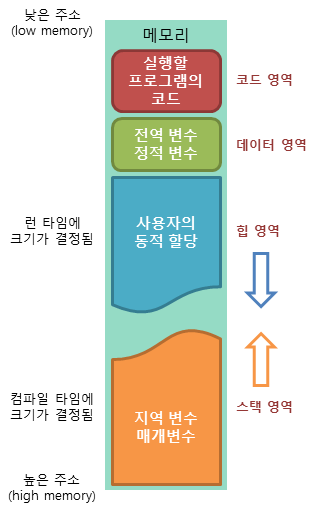
- 코드 영역: 실행할 프로그램의 코드가 저장되는 영역으로 텍스트 영역이라고도 부른다. 사용자가 프로그램 실행 명령을 내리면 OS가 HDD에서 메모리로 실행 코드를 올리게 되고, CPU는 코드 영역에 저장된 명령어를 하나씩 처리하게 된다.
- 데이터 영역: 프로그램의 전역 변수(global)와 정적 변수(static)가 저장되는 영역이다. 데이터 영역은 프로그램의 시작과 함께 할당되며, 프로그램이 종료되면 소멸한다.
- 힙 영역: 프로그래머가 직접 관리할 수 있는 메모리 영역으로 이 공간에 메모리를 할당하는 것을 동적 할당이라고 부른다. Java에서는 가비지 컬렉터가 자동으로 해제해준다. 힙 영역은 스택 영역과 달리 낮은 주소에서 높은 주소로 메모리가 할당된다.
- 스택 영역: 함수의 호출과 함께 할당되며 지역 변수와 매개 변수가 저장되는 영역이다. 스택 영역에 저장되는 함수의 호출 정보를 스택프레임이라고 한다. 스택 영역은 함수의 호출이 완료되면 소멸한다. 스택 영역은 높은 주소에서 낮은 주소로 메모리가 할당된다.
메모리 구조 심화 - Java 와 JavaScript
- 핵심 요약: 관리 주체와 방식의 차이 : Java와 JavaScript는 둘 다 자동 메모리 관리(가비지 컬렉션)를 사용하지만, Java는 JVM(자바 가상 머신) 위에서 보다 체계적이고 개발자가 직접 관여할 수 있는 옵션이 많은 반면, JavaScript는 브라우저의 엔진에 의해 더 추상화되고 자동화된 방식으로 메모리를 관리한다.
Java의 메모리 사용 방식
- Java 애플리케이션은 JVM(Java Virtual Machine) 위에서 실행되며, JVM은 운영체제로부터 할당받은 메모리 영역(Runtime Data Area)을 용도에 따라 여러 부분으로 나누어 관리한다.
- 메서드(Method) 영역: 클래스, 변수, 메서드 등과 같은 클래스 정보가 저장된다. 이 영역은 모든 스레드가 공유한다.
- 힙(Heap) 영역:
new키워드로 생성된 객체와 배열이 저장되는 공간이다. 가비지 컬렉터(Garbage Collector)가 주로 활동하는 영역으로, 더 이상 참조되지 않는 객체를 찾아 메모리에서 해제한다.- Young Generation: 새롭게 생성된 객체가 위치한다. 이곳에서 많은 객체들이 생성되고 빠르게 사라진다.
- Old Generation: Young Generation 영역에서 오랫동안 살아남은 객체들이 이동하는 곳이다.
- 스택(Stack) 영역: 메서드 호출 시 생성되는 지역 변수, 매개변수, 리턴 값 등이 저장된다. 메서드 호출이 끝나면 해당 스택 프레임은 자동으로 사라지므로 데이터도 함께 제거된다. 각 스레드마다 별도의 스택이 생성된다.
JavaScript의 메모리 사용 방식
JavaScript는 주로 웹 브라우저의 JavaScript 엔진(예: Chrome의 V8)에 의해 메모리가 관리된다. Java와 유사하게 힙과 스택을 사용하지만, 개발자가 직접 제어할 수 있는 부분은 거의 없다.
- 메모리 생명 주기: JavaScript의 메모리 관리는 할당, 사용, 해제의 3단계 생명 주기를 따른다.
- 할당 (Allocation): 변수 선언, 함수 정의, 객체 생성 시 엔진이 자동으로 메모리를 할당한다.
- 사용 (Use): 할당된 메모리에 값을 읽고 쓰는 작업을 한다.
- 해제 (Release): 더 이상 필요 없는 메모리는 가비지 컬렉터에 의해 자동으로 회수된다.
- 메모리 공간:
- 콜 스택(Call Stack): 함수가 호출될 때마다 해당 함수의 실행 컨텍스트(함수 정보, 인자, 지역 변수 등)가 순서대로 쌓이는 곳이다. 원시 타입(Primitive types) 데이터가 이곳에 저장된다.
- 힙(Heap): 객체, 배열, 함수와 같이 크기가 정해지지 않은 참조 타입(Reference types) 데이터가 저장되는 공간이다. 콜 스택에는 힙에 저장된 데이터의 주소(참조)만 저장된다.
- 가비지 컬렉션: JavaScript 엔진은 ‘도달 가능성(reachability)’ 개념을 사용하여 더 이상 참조되지 않는 객체를 찾아 메모리에서 제거한다. 특정 객체에 접근할 수 있는 경로가 하나도 없으면 가비지 컬렉션의 대상이 된다.
주요 차이점 정리
| 구분 | Java | JavaScript |
|---|---|---|
| 실행 환경 | JVM (Java Virtual Machine) | JavaScript 엔진 (e.g., V8, SpiderMonkey) |
| 메모리 구조 | 메서드, 힙, 스택 등으로 명확하게 구분 | 콜 스택, 힙으로 단순하게 구분 |
| 데이터 타입 | 원시 타입은 스택, 참조 타입은 힙에 저장 | 원시 타입은 콜 스택, 참조 타입은 힙에 저장 |
| 개발자 제어 | 힙 크기 조절, GC 알고리즘 선택 등 일부 제어 가능 | 메모리 관리에 거의 관여할 수 없음 |
JVM을 계속 쓰는 이유는?
초기 JVM은 코드를 한 줄씩 해석하는 인터프리터 방식의 비중이 높아 속도가 느리다는 평가를 받았지만, 오늘날의 JVM은 다음과 같은 기술들을 통해 높은 성능을 보여준다.
- 고도로 발전된 JIT(Just-In-Time) 컴파일러
- 프로파일링 기반 최적화: JVM은 단순히 코드를 기계어로 번역하는 것을 넘어, 애플리케이션이 실행되는 동안 코드의 어떤 부분이 자주 사용되는지(‘뜨거운’ 코드)를 지속적으로 분석한다.
- 적응형 최적화(Adaptive Optimization): 자주 사용되는 코드는 더욱 공격적으로 최적화된 기계어로 재컴파일한다. 예를 들어, 처음에는 빠르게 컴파일하고(C1 컴파일러), 해당 코드가 계속해서 많이 쓰이면 시간을 더 들여 최고 수준으로 최적화한다(C2 컴파일러). 이런 동적인 최적화 방식 덕분에 시간이 지날수록 애플리케이션의 성능이 점차 향상된다.
- 혁신적인 가비지 컬렉터(GC)의 발전
- 과거의 GC는 메모리를 정리하는 동안 애플리케이션 실행이 멈추는 ‘Stop-the-world’ 현상 때문에 성능 저하의 주된 원인이었다.
- G1 GC (Garbage-First): Java 9부터 기본 GC로 채택되었으며, 전체 힙(Heap) 영역을 작은 구역(Region)으로 나누어 관리한다. 이를 통해 짧은 멈춤 시간(Pause Time)을 예측 가능하게 유지하면서도 효율적으로 메모리를 정리한다.
- ZGC 및 Shenandoah GC: 최신 Java 버전에 도입된 이 GC들은 멈춤 시간을 수 밀리초(ms) 단위로 극단적으로 줄이는 것을 목표로 한다. 수백 기가바이트(GB)에 달하는 거대한 메모리를 사용하는 시스템에서도 애플리케이션의 중단 없이 메모리를 정리할 수 있어, 대규모 서비스에서 매우 중요한다.
- JVM 자체의 내부 최적화
- 이스케이프 분석(Escape Analysis): 객체가 특정 메서드 안에서만 사용되고 외부로 벗어나지 않는다고 판단되면, 비싼 메모리 공간인 힙(Heap)이 아니라 훨씬 빠른 스택(Stack)에 객체를 할당한다. 이는 GC의 부담을 크게 줄여준다.
- 프로젝트 룸(Project Loom): 최신 Java에 도입된 ‘가상 스레드(Virtual Threads)’ 기능이다. 기존 스레드보다 훨씬 가볍게 만들 수 있어, 적은 자원으로 수백만 개의 동시 작업을 처리할 수 있게 해준다. 이는 JVM 수준에서 동시성 처리 방식을 근본적으로 개선한 것이다.
JS 가 과거보다 빨라진 이유는?
기존의 JS의 철학, 그리고 이를 구동하는 엔진은 편리했으나 한계가 많았다. 비표준의 엉망인 상황에 성능까지 좋지 못했으나, V8 엔진은 다음과 같은 핵심 기술들을 통해 JavaScript의 성능을 크게 향상시킨다.
- JIT (Just-In-Time) 컴파일러 도입
- 과거 방식: 코드를 한 줄씩 읽고 해석하는 인터프리터(Interpreter) 방식을 무조건적으로 사용해 속도가 느렸다.
- V8 방식: JavaScript 코드를 실행 직전에 기계어(Machine Code)로 컴파일한다. 이는 사람이 이해하는 언어를 컴퓨터 CPU가 직접 이해하는 언어로 미리 번역해두는 것과 같아 실행 속도가 매우 빨라진다.
- 최적화 컴파일러: 이그니션(Ignition)과 터보팬(TurboFan)
- V8은 단순히 코드를 번역하는 것을 넘어, 2단계에 걸친 최적화 전략을 사용한다.
- 이그니션 (Ignition): 먼저 코드를 빠르게 실행하기 위해 바이트코드(Bytecode)로 변환한다. 이는 시작 속도를 빠르게 만들어 준다.
- 터보팬 (TurboFan): 코드가 실행되는 동안, 자주 사용되는 ‘뜨거운(hot)’ 부분을 감시한다. 그리고 이 부분을 매우 최적화된 기계어로 다시 컴파일하여, 반복적인 작업의 성능을 극대화한다.
- 객체 속성 접근 속도 향상: 히든 클래스(Hidden Class)
- JavaScript는 객체의 구조가 동적으로 바뀔 수 있어 속성 접근이 느릴 수 있다.
- V8은 비슷한 구조의 객체들을 내부적으로 같은 ‘히든 클래스(Hidden Class)’로 묶어 관리한다. 이를 통해 객체의 속성이 메모리의 어디에 위치하는지 미리 예측하고 빠르게 접근할 수 있게 된다.
- 가비지 컬렉션(GC) 최적화
- 더 이상 사용하지 않는 메모리를 정리하는 가비지 컬렉션 과정이 프로그램의 실행을 잠시 멈추게 할 수 있다.
- V8은 이 멈춤 현상(stop-the-world)을 최소화하기 위해, 여러 개의 스레드를 활용하여 병렬적으로 메모리를 정리하고, 세대별(Generational)로 나누어 효율적으로 관리하는 등 다양한 최적화 기법을 사용한다.
Docker 개요 정리
Docker는 애플리케이션을 ‘컨테이너’라는 격리된 표준 단위로 패키징하여 개발, 배포, 실행하는 개방형 플랫폼이다. 컨테이너는 코드, 라이브러리 등 애플리케이션 실행에 필요한 모든 것을 포함하고 있어, 개발자의 PC부터 실제 운영 서버에 이르기까지 어떤 환경에서든 동일하게 동작하는 것을 보장한다. 이를 통해 “제 컴퓨터에서는 잘 되는데요?”와 같은 고질적인 문제를 해결하고, 소프트웨어를 빠르고 일관되게 전달하는 CI/CD(지속적 통합/배포) 과정을 효율적으로 만든다.
이러한 Docker는 사용자의 명령을 받는 클라이언트와 실제 컨테이너를 관리하는 데몬(서버)으로 구성된 구조로 동작한다. 개발자는 읽기 전용 템플릿인 ‘이미지’를 바탕으로 실행 가능한 인스턴스인 ‘컨테이너’를 생성하고 관리하게 된다. 이러한 방식은 기존의 가상 머신(VM)보다 훨씬 가볍고 빨라 서버 자원을 효율적으로 사용할 수 있게 하며, 높은 이식성으로 어떤 환경으로든 애플리케이션을 쉽게 이전하고 확장할 수 있는 장점을 제공한다.
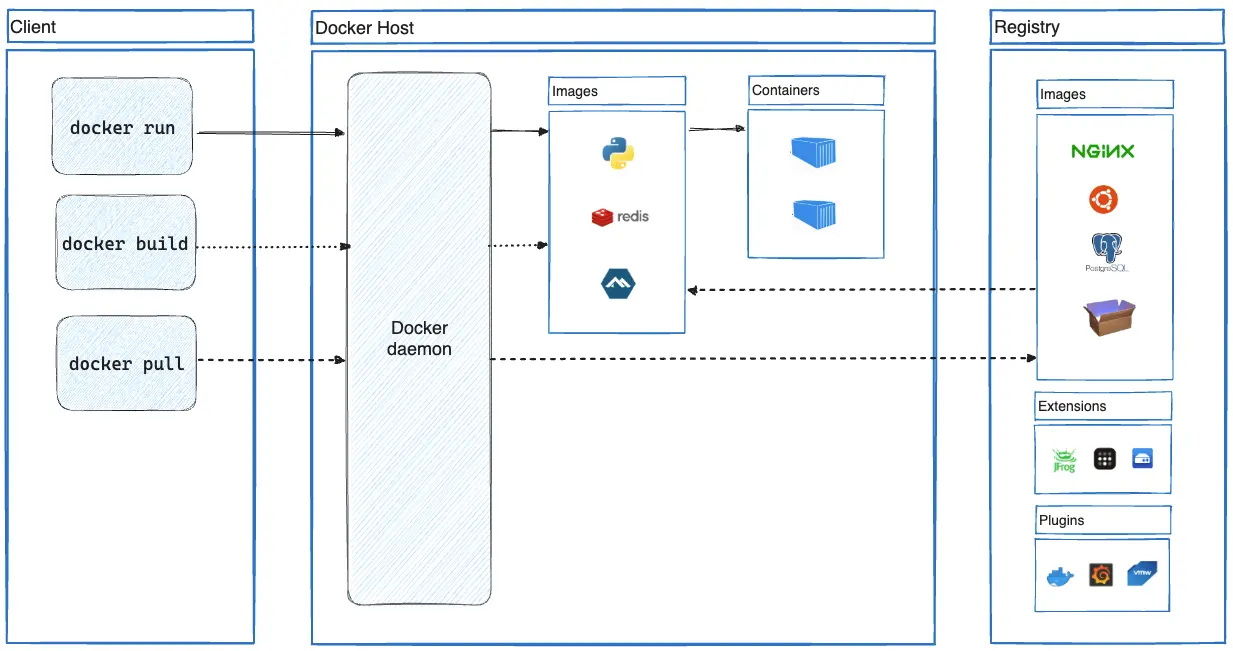
하나 알 게 된거… 클라이언트 - 서버 구조니 데몬과 클라이언트를 조작하면 원격지에 데몬을 내 컴퓨터에서 조작하는 것도 가능해지는 구나..!
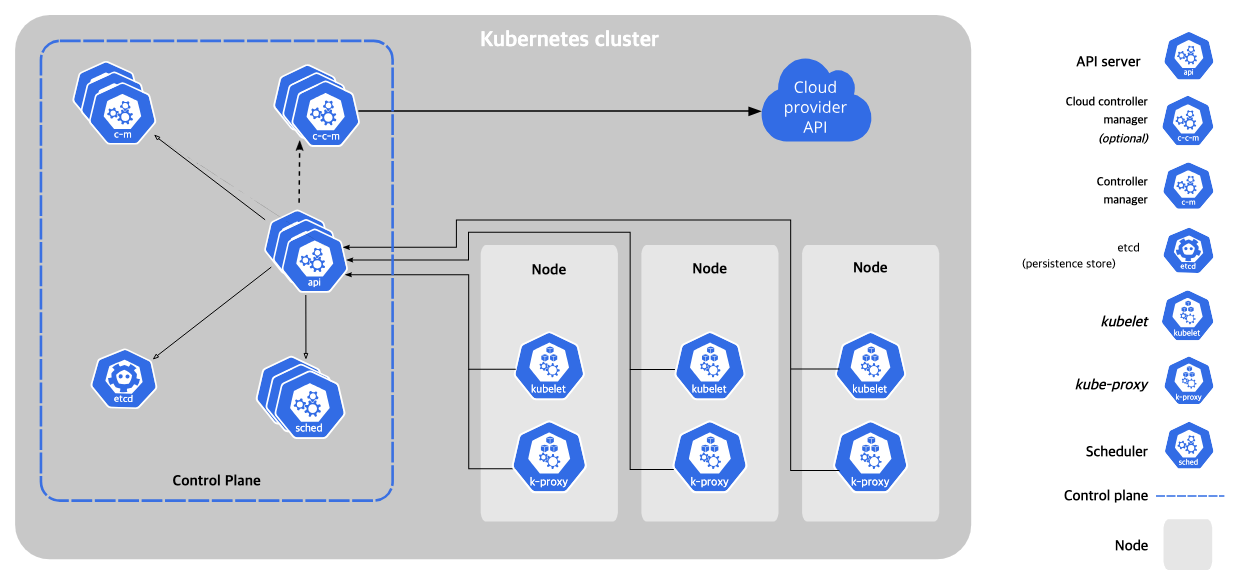
Kubernetes 개요 정리
Kubernetes는 분산 시스템을 탄력적으로 운영할 수 있는 프레임워크를 제공한다. 컨테이너가 다운되면 자동으로 새 컨테이너를 시작하고, 트래픽이 증가하면 로드밸런싱을 수행하며, 애플리케이션의 스케일링과 장애 조치를 자동화한다. 주요 기능으로는 서비스 디스커버리, 스토리지 오케스트레이션, 자동 롤아웃/롤백, 자가 치유, 시크릿 관리, 수평 확장 등이 있어 개발자가 인프라 관리보다는 애플리케이션 개발에 집중할 수 있게 해준다.
Kubernetes는 기존 PaaS와 달리 특정 애플리케이션 타입을 제한하지 않으며, 소스 코드 배포나 빌드 기능은 제공하지 않는다. 대신 컨테이너 수준에서 작동하여 개발자에게 선택권과 유연성을 제공하는 빌딩 블록 역할을 한다. 물리 서버 → 가상화 → 컨테이너로 이어진 인프라 진화 과정에서, 컨테이너는 VM보다 경량이면서도 OS를 공유하여 리소스 효율성을 높이고, 개발부터 프로덕션까지 일관된 환경을 제공하는 현대적 배포 방식의 핵심이다.