 Paul's Archives
Paul's Archives

들어가면서
본 문서는 과거 React Shell 취약점으로 인한 L7 공격 경험을 바탕으로, ‘고가용성 트래픽 제어 시스템’을 구축하는 과정을 기록한 첫 번째 성장 일지입니다. Kubernetes의 복잡성에서 벗어나 실용적인 Docker 기반 아키텍처로 전환하고, 러너스 하이 2기를 위한 ‘유량 제어 안정성’을 핵심 목표로 설정하여 측정 가능한 기술적 임팩트를 증명하고자 하는 제 1번 기록입니다.
퇴사
몸의 건강의 문제, 그리고 다음을 준비해야 하는 문제를 포함하여 나의 2024년과 25년은 그야말로 달리는 한 해였다. 42서울의 3년의 시간, 그리고 1년의 서버 개발자로의 활동은 분명 숨고를 틈이 없었다.
숨을 고르는 것, 동시에 지금까지 한 작업들이 꽤나 괜찮은 작업들이었음은 맞다고 생각되나, 몇 가지 아쉬움이 있었다.
- ‘연차’를 뛰어넘는 개발자가 되고 싶다는 내 생각에 비해 아직 못 미친다는 생각.
- 과연 기술적으로 내가 했던 것들이 증명이 된 것이 맞을까?
- AI를 비롯한 신 기술의 ‘응용 개발자’가 되기 위한 발판이 마련되어야 한다. 지금은 업무로 모든 것을 할 시간이 부족하다.
개발자로 어느정도 안착은 했지만, 해야할 일, 할 수 있는 일 사이에서의 고민과 좀더 괜찮은 공간, 괜찮은 커뮤니티, 괜찮은 리소스에서 제대로 일하고 싶다는 생각을 해왔고, 마침 회사의 노선 변경을 눈앞에서 지켜보던 찰나, 내가 할 수 있는 선택과 결단이 필요하단 생각이 들었기에 퇴사를 하고 프로젝트를 진행하기로 마음을 먹게 된다.
그리하여 시작한 것이 퇴사 후 Project Protostar AI 기반의 챗봇 서비스의 구현이었다.
한계 봉착. 하지만 그럼에도 발견한 새로운 가능성
Project Protostar 의 시스템 검증, n8n 을 기반으로 한 AI PoC 구축은 생각보다 너무 쉽게 이루어져 갔다. 바이브코딩 역시 한몫을 했는데, 특히나 Antigravity, PRD 구조의 수동 구축 및 AI 적용 등을 통해 AI 가 개발의 보조 역할을 톡톡히 해준다는 점은 지울 수 없는 특이점이었고, 단 수일로 프로젝트의 FE, BE 틀 까지는 만들 수 있었다.
하지만 문제가 있었으니.. 그것이 바로 DevOps 의 영역에 대한 문제였다. CI나 CD 는 Jenkins와 ArgoCD 기반으로 어떻게 하는지를 배우고 나니 생각 이상으로 빠르고 명료하게 해내갈 수 있었고, 에러가 발생했을 때 어떻게 하면 될지도 느낄수 있었는데… 문제는 K8s 의 적용에 있었다.
TIL - 11월, K8s 실패 + Docker 환경으로의 전환 정리 이 글에서도 디테일 하게 정리했었지만… k8s 실무 버전을 위해선 중요한 게 failover 와 self-healing 을 위한 일종의 전체 패키지의 구축된 이미지들의 덩어리를 차트 형태로 가져갔으며, 이 차트들은 제각기 다른 의존성과, 설정으로 아주 예민하게 묶여 있었다. 문제는 그런 시스템을 혼자서 개발하려고 했단 것 자체가 엄청난 문제였고, 쏟아지는 버그와 러닝커브를 내 프로젝트 기간 내에 전부 녹여 낼 수 있으리란 생각이 들지 않았다. 심지어 AI 조차도 학습된 시차가 존재하는데, 문제는 그 학습이 ‘버전 별 차이’를 가지고 하는게 아니라, 과거 버전의 혼합된, 그리고 현재의 구성요소는 제대로 인지도 못하고 있는 상황이었다. (ChatGPT, Claude, Gemini 모두다). 결국 이 영역의 현업에서 사용하기 어려운 수준의 버전을 쓰는 꼴이었고, 그 마저도 제대로 현재의 정책이 달라져 헬름 차트 공개 위치가 달라지는 등의 문제를 그대로 않고 있었다.
특히 가장 핵심은 ‘URL’ 과 같은 유니크한 정보였다. AI 의 본질이 확률, 가능성을 기반으로 형성된 확률 계산기인 만큼, 사실 엄청난 양의 패러미터 사이즈를 가진다고 해도, 여기서 문제는 그것이 ‘정확한 정보’ 이냐 반대로 ‘그럴듯한 정보’냐 라는 지점이 문제시 된다. 그리고 실제로도 그 문제로 오히려 더 많은 시간을 소모했다. 헬름 차트 URL 을 못찾아 온다거나, 정책이 바뀌어 오픈하지 않는 경우 등이 이에 해당되었다.
결국 이러한 상태로 지지부진한 것은 프로젝트 전체를 위해 도움이 되지 않는 다고 판단했다. 못하는 건 다시 배우면 된다 치고, 러닝 커브는 돌파하기 어렵다면 지금은 우선 가능한 최선의 선택을 할 뿐이었다.
토스 그리고 Focus On Impact
그리하여 어떻게 어떻게 다시 프로젝트를 이어 가던 도중, 갑작스럽게 링크드인을 통해 이런 공고를 볼 수 있었다.
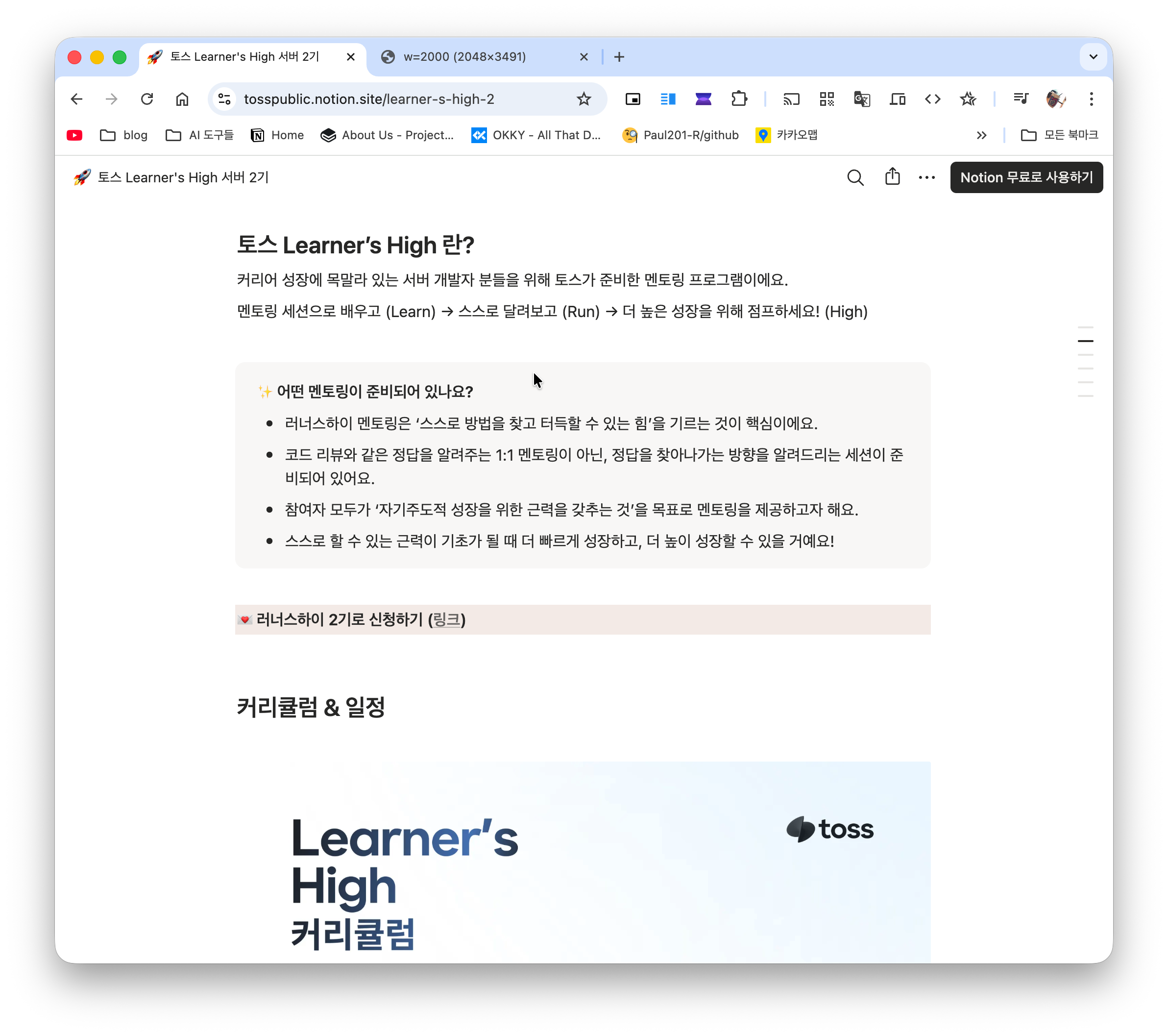
러너스 하이? 스스로의 성장을 증명하라? 해당 포인트는 너무나 완벽하게 나에게 부합하는 부분이었다. 거기다 작업하는 과정에서 고민이 되는 것이 있었다.
- 이전에 설명했듯, 구상과 구현이 어떻게 하면 되는지 다 아는데, 핵심인 k8s 를 내려놓고 개발만 하는게 맞을까?
- 그리고 이러한 전체를 구현하는 것은 정말로 내가 개발자 스러운 전문성을 확보하는 걸까?
- 나의 증명을 하겠다고 했지만, 과연 나 혼자만의 북치고 장구치고가 된다면 그건 증명이 맞을까? 이러한 질문들은 꼬리를 약간 물고 있었는데, 그러던 와중에 보인 이 광고. 그리고 정말 심플하게 적혀져 있는 토스의 문구는 나를 자극하기 충분했고, 노려볼만 하겠구나 라는 생각을 할 수 있었다.
“결국, 시작이 반이라고 일단 할 수있는 최대한 빨리 지원하자!”
이런 결정이 든 순간, 프로젝트를 약 3일 정도 멈추고, 최대한 빨리 이력서와 경력 기술서를 작성 했고, 놀랍게도…
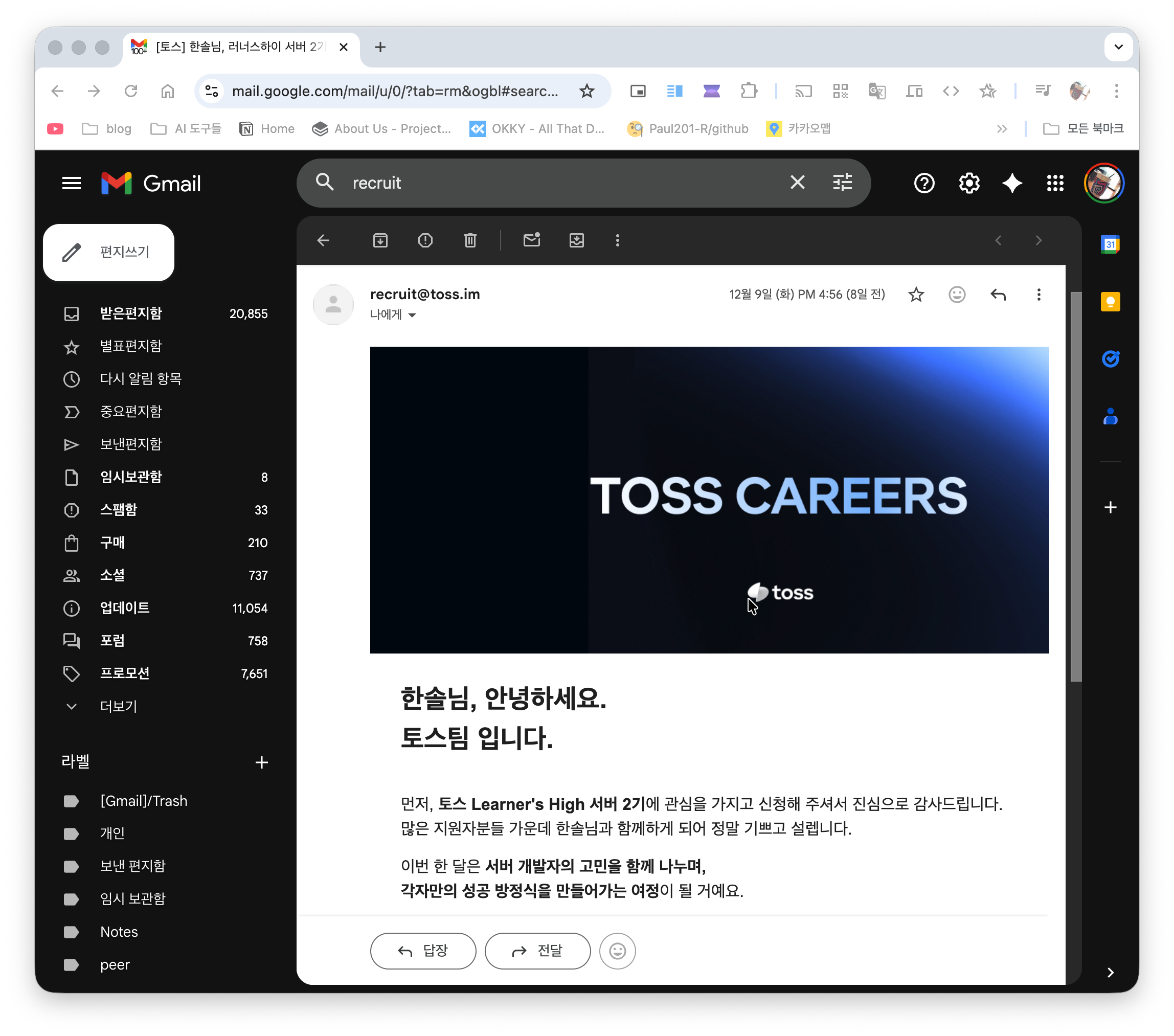
기회가 찾아왔다
그래서 뭘 하지?
Focus
기회를 받아냈다. 검증할 기회. 집중할 수 있는 기회. 도망칠 수 없는 기회.
기쁘지만 동시에 이젠 진짜 구나 라는 실감이 프로젝트를 홀로 할 때보다 확실하게 들었고, 특히나 오리엔테이션이 끝나고 나서, 한달이란 시간 내에 어떤 걸 해보면 좋을까? 에 대한 생각은 내 머릿속을 관통했다.
그리곤 오리엔테이션의 내용과 함께 1기에 먼저 참가했던 분들의 후기들, 그리고 그 속에서 나는 어떤 걸 해야 할까? 고민하게 되었다. 특히나 가이드를 통해, 서버의 헤드이자 연사로 나온 이항렬님의 이야기를 들으면서 다시 생각해보기 시작했다.
Project Protostar 를 물론 만드는 것도 중요하다. 증명한다면 좋겠지. 하지만 지금은 한달이란 기간의 극적인 효과를 낼 수 있어야 할 것이고, 특히나 스스로 성장할 포인트를 잡고 ‘완수’ 해내는 것이 너무나 중요하다. 하지만 실상 본질은 아니었다. 엄밀히 말하면 만들어 내든 안내든 그게 무슨 의미인가? 그것이 전문가가 되기 위한 명확한 근거가 되는가?
코드의 가치는 AI 를 통해 한없이 낮아졌다. 결국 그것이 날 대표할 순 없고, 나의 실무적 가치는 그것을 넘어서야 하는 거고, 그렇게 하기 위핸 더 깊은 어딘가, 실무에서든 어디에서든 분명하게 스스로 문제를 규정하고 풀어내고, 그 속에서 결과를 만들어내는 것이 기획자도 아니고, 프론트엔드 개발자도 아닌 내가 만들어낸 얄팍한 서비스를 들이밀며 ‘난 백엔드 개발자야’ 라고 이야기 할 순 없지 않겠는가?
Problem…?
그러다 문뜩, 내 블로그에 적었던 나의 글이 떠올랐다. 기록하고 프로젝트를 다 하곤 보완하리라 생각하고, 현재는 응급 처치를 해둔 보안 결함성 문제.
React2Shell 이라는 문제로 인해 NextJS 15 이상, React 19 이상인 프론트엔드 서버에서 내부에서 서버에 공격을 가하는 것이었으며, CPU 자원을 800% 나 끌어다 썼던 일. 방법이야 어찌 되었던 간에 L7 의 공격이 들어올 때 Rate Limiter 의 부재를 비롯, 여러 면에서 Traffic Dam 이 없었다는 점에서 공격을 허용한다는 것은 백엔드 개발자이자, 백엔드 인프라 차원에서 해결할 수 있어야 하지 않았을까?
그렇게 생각하니 퍼즐이 머릿속에서 맞춰지는듯 했다. 그렇다 내가 원하는 건 물론 이것 저것 다 재밌게 잘 하는 것도 재밌을 것이다. 하지만 더 중요한건, 본질은 내가 서버 개발자이며, 서버 개발자로서 실무적으로도, 본질적으로도 해야할 일을 심화 하는 것. 그것이 얄팍한 올라운더보다 현재 가장 중요한게 아니겠는가?
그리하여 해야할 일을 몇 가지로 추려 보았다.
- 대기열 순서 보장
- 유량 제어 안정성
- 장애 복원력 그러나 여기서 React2Shell 같은 케이스가 발생 시 백엔드 서버에서 직접적인 해결책이 되기도 하며, 현재 상황에서 가장 현실적인 플랜으로 생각할 때 2번을 성공적으로 달성해 내는 것이 어떨까! 싶었기에 그것을 구현해 내려고 한다.
그렇다면 증명하고 구현할 것들의 로드맵은?
| 주차 | 목표 | 핵심 작업 |
|---|---|---|
| 1주차 | MVP + Baseline 측정 | 챗봇 API 연결, “Dam 없는 상태”에서 부하 테스트 → Before 수치 확보 |
| 2주차 | Traffic Dam 핵심 구현 | Rate Limiter (Token Bucket) + BullMQ 대기열 + Backpressure 로직 |
| 3주차 | 스트레스 테스트 | k6로 5,000 RPS 공격 시뮬레이션, Dam 있는 상태 → After 수치 확보 |
| 4주차 | 비교 분석 + 문서화 | Before/After 그래프, Grafana 대시보드 캡처, 성장 일지 마무리 |
“초당 5,000개의 악의적 요청이 들어와도, 백엔드는 초당 100개만 처리하며 죽지 않는다”
챗봇, 특히 LLM 은 이용하기에 좋은 먹잇감이며, 특히나 그 구조 상 AI 를 혹사 시킬 수도 있다. 그러다보니 프론트엔드에서 제한을 걸긴 하지만, 그럼에도 API 사용 시 제한으론 부족함도 있었다. 그렇다면, 내 API 비용(?) 을 포함 여러가지를 지켜낼 수 있는 것들을 위의 일정을 거쳐 구현해내고 검증하면 어떤가? 하고 생각했다.
Docker를 기반으로 Grafana, Prometheus, exPorter, cAdvisor, loki-promtail이 설정 되어있다. 배포도 준비 되어 있고, 챗봇도 일단 겉 모습은 되어 있으니 그걸 그대로 쓴다면? 현재의 문제를 묘사해보고, 실제 그런 일이 발생시 버틸 능력을 기른다. 이것은 어쩌면 광활하고 얕은 프로젝트를 마무리 짓기 보다 우선시 하는게 낫지 않겠는가!
기술적 Base why
해당 Traffic Dam 아키텍쳐를 구현하는 것은 기존에도 Protostar 프로젝트의 Polyglot 구조를 그대로 차용할 것이다. 이는 AI의 작업에 맞는 프레임워크와 웹 서버 본질에 충실한 NestJS 를 혼용함으로써 각각의 장점을 극대화 하려는 측면이 있기 때문이다. 특히나 두 서비스의 Redis 기반의 느슨한 결합을 통해 하드웨어적으로 모니터링과 서비스를 단일지점장애가 발생하지 않도록 설계하였듯, 각각의 컨테이너도 서로의 장애가 전파되지 않도록 할 것이다.
측정 계획은?
로드맵에 나온 측정은 아직 완벽하게 어떤 툴을 쓸지를 정한 것은 아니다. 그럼에도 구체적으로 고민과 진득한 AI와의 씨름 끝에 합당할 만한 수치들을 정리해보면 다음과 같았다.
- 시스템 안정성 : ‘시스템이 공격을 버티는 가’
- 에러율(Error Rate)
- 성공적 요청 처리량(Worker TPS)
- 서버 재시작 횟수(OOM)
- 리소스 효율성 : ‘얼마나 효율적으로 버텨내는가?’
- CPU 사용률(CPU Usage %)
- 메모리 사용률(Memory Usage)
- FD 사용량: 해당 수치는 다만 간단한 구현 과정에서 의미가 없을 수도 있다고 생각함
- 사용자 경험 및 큐 성능
- API 응답 시간(Latency)
- 대기열 길이(Queue Length)
- 평균 대기시간(Avg. Wait Time)
리스크 & 가정
단 생각해보니 현재는 AWS 구축을 고려한 설계와 호환성을 갖춰둔 구조를 취하고 있지만, 그럼에도 온프레미스 라는 점을 감안할 때 몇가지 가정이 필요하다는 생각은 들었다.
- 온프레미스 환경에서 모니터링과 서비스 서버 각 1대가 별도의 네트워크로 HTTPS, HTTP 를 모두 할당 받은 상태이므로 기본적으로 연결에서 안정성은 문제가 없다.
- 현재의 온프레미스 서버는 기본적으로 라이젠 칩셋이 탑재된 40GB 의 메모리를 가진 서버로, 일반적인 서버 리소스보다 매우 넉넉한 환경을 갖고 있으며 이를 고려한 고 가용성 테스트로 수치를 점점 늘려 나갈 것이다. (반대로 서버의 성능을 제한을 걸어 테스트를 해야할 필요도 있어 보인다. 더 제약이 걸린 리소스 상태로 최대 처리를 재는게 더 현실적일 순 있으니)
- 아주 최악의 상황일 수 있는 것으로 공유기가 한계치에 부딪힐 수 있다는 점인데, 현재의 상황은 다음과 같다.
- WIFI 7을 지원하는 최신 성능의 칩셋 탑재 공유기 사용중
- 해당 공유기의 리소스를 최소화하고자 해당 공유기는 모두 유선 연결이 기본이며, 집의 wifi 는 메인 공유기에서 쓰지 않고 서브 공유기를 통해 수행되어, 리소스 사용을 오로지 서비스 자체에 집중한다. (AP 모드)
- 만약 공유기가 먼저 문제가 발생한다면, 이 역시 Docker 자체의 하드웨어를 제약을 걸어 놓고, 이를 기반으로 적용된 Traffic Dam 로직을 기반으로 얼마나 성능과 지표가 나오는지를 본다.
- 위의 점을 기반으로 볼 때, 핵심은 주어진 단일 노드의 물리적 한계 내에서 소프트웨어 아키텍처 만으로 어디까지 트래픽을 제어할 수 있는지 증명하는 것이기에, 네트워크 지연, 분산 시스템의 복잡성은 제외한다.
결론
너무나 감사하게도 1차적으로 선발될 수 있었기에, 그 기회를 제공 받았단 말 만으로도, 나의 노력들이 헛으로 쓰이진 않았구나 라는 생각을 할 수 있었다. 1년간 치열하고 치밀하게 달려온 것들, 정리한 것들이 결국 다 나의 경험이자 가치이며, 내가 개발자로 살아갈 수 있구나를 토스가 다시 한 번 검증해준 것 같아 기분이 좋았다.
결국 실력의 검증, 그 실력의 증명을 내 나름의 방식으로 해결했단 것이고, 이걸 기반으로 확장해 나가면 되지 않겠는가? 그리고 그런 와중에 새롭게 해야할 일을 빠르게 찾아갈 수 있었고, 그 목표 역시 지금 내가 판단할 방법은 없지만, 분명 토스가 원하는 것에 합당하리라 생각이 들었다.
정형화된 방식을 그대로 따르기 보다, 각자의 환경에 맞는 최적의 해답을 스스로 탐색해나가는 시간
러너스 하이 2기의 내부 내용은 공개할 수도 없고, 애초에 평가 방식이라던가 이런 미공개인 관계로 나도 모르지만, 어쨌든 이 문제를 개선해보고 직접 로깅하고 데이터를 비교하면서 제대로 백엔드를 구현해낸다면? 어쩌면 다음 단계의 내 모습이 나를 기다리고 있으니 해야 할 일은 정해져 있었다. 제한된 리소스를 최대한 활용하고, 활용한 결과를 냉정하게 분석하고 개선한다.
턱 밑까지 숨이 차오를 수 있도록, 그리하여 달리다가 서서히 아픔이 사라지고, 끈덕지게 문제를 해어 나가는 과정에서 새로운 지평선이 보일 수 있도록.
노력해야겠다.