 Paul's Archives
Paul's Archives
Project Protostar 를 소개합니다
Forge Your Future
![]()
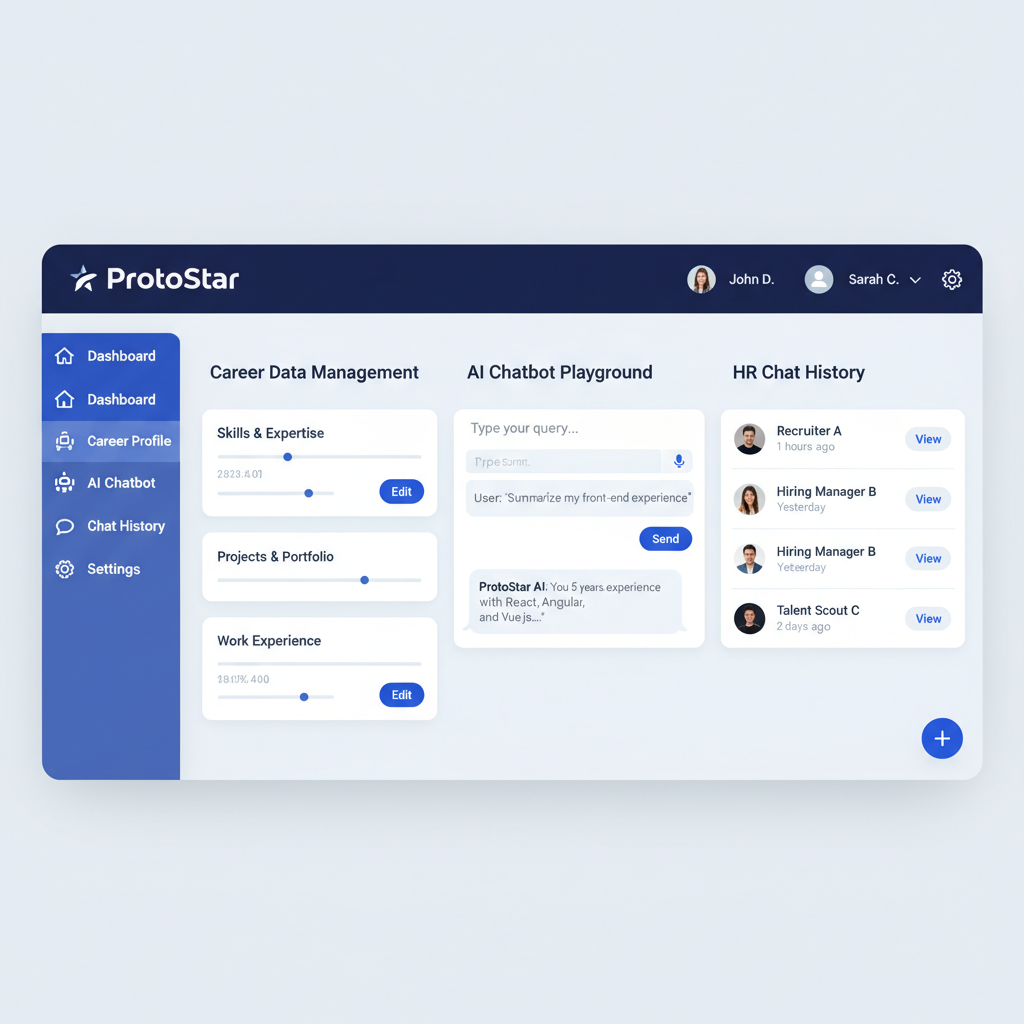
회사가 뭘 원할까?
이 질문은 회사를 다니는 경력자들조차 쉬이 확답으로 이야기 하기 어려운 영역이다. 전문성, 어떤 영역에서 깊이 있게 된 사람이라면 모를까, 그렇지 않다면 항상 어려운 이야기일 것이다.
이 사람은 과연 잘 할까?
이 질문 역시 HR을 하는 조직, 회사 입장에서 항상 어려운 영역이다. 전문성과 체계화를 통해 이를 시스템으로 정착 시킨 회사라면 그나마 괜찮겠지만, 그렇지 않은 회사들이 절대적이며, 그렇기에 많은 회사 경영진들은 비싼 돈을 주고서도 인사 관리, 어떻게 사람을 뽑고, 쓰며, 배치 할지에 돈과 시간을 쏟아붓는다.
그런 생각 도중에 이렇게 생각했다?
커리어에 대한 현실적인 질문을 노동자가 받을 수 있다면? 커리어에 대한 방대한 자료들에 직접 핵심으로 생각하는 질문을 하고, 그거에 능동적으로 답변이 가능하다면?
이력서는 압축이 필요하다 경력 기술서도 압축이 필요하다 자기 소개서도 압축이 필요하고 무엇보다 ‘매력적’인 부분을 어필해야한다.
HR 담당자의 시간은 금인데, 일일히 읽어보는게 아닌, 핵심으로 생각하는 질문을 던질 수 있고, 이에 준하는 사람을 능동적으로 찾아낼 수 있다면? 자연어로 구성된 복잡한 질문을 풀어낼 수 있다면?
또 반대로 HR 담당자가 어떤 질문을 하고, 어떤 부분을 관심 가지는지 알 수 있다면?
‘Forge Your Future’ 이라는 슬로건은 이러한 문제에서 시작하였다.
기술적 성장 포인트
현재 3년간의 과정을 통해 나의 기술적 능력치는 상당히 끌어 올려졌다. 특히나 1년 간의 메인 백엔드 개발자로서의 일은, 물론 남들에겐 제대로된 사수가 없다는 사실에, 박봉이란 사실에 아쉬워 하거나, 저걸로 되겠냐? 라고 생각하고 질문하시는 분도 있었다.
하지만 그것은 나에겐 너무나 소중한 시간이었다. 온전한 책임, 온전한 집중이 가능하고, 다른 사람이 아닌 내가 실제 부딪혀서 생기는 불만과, 부족함, 그리고 어려움을 직접 고민해볼 수 있는 ‘권한’이 제공되었다는 점만으로도 감사했고, 그 감사한 순간에 하루가 다르게 성장하는 AI는. 비록 완벽하진 않지만, 그럼에도 불구하고 내가 써야할 다양한 기술들의 적용, 방법, 핵심을 잘 설명해주는 완벽한 비서였다.
그렇기에 1년하고도 수개월 간을 달려올 수 있었고, 그 달려옴으로 생긴 문제도 쉴 겸. 그리고 그걸 기반으로 더 큰 성장을 이루기 위해 이번 프로젝트를 기획하게 되었다. BM 차원에서나, 기획 차원에서 아쉬움도 있을 수 있고, 한계점이 명백하다고 생각은 한다. 그럼에도, 실제 구현을 해냈다. 그리고 동시에 이를 어떤 구조에서 세워 나갔는가! 를 더 중요시하기로 했기에, 몇가지 기술적 구현 목표를 설정했다.
- v1 : 초기 MSA 기반 설계, Kubernetes 를 기반으로 하는 엔터프라이즈급 구성, 스케일링, 무중단(zero-downtime) 을 구축하는 걸 목표로 하고 AI와 DevOps 역량을 극대화 하자.
- v2 : 국내 시장의 요구사항을 점검하여 몇 가지 기술 스택을 개선하고, 특히 k8s 기반의 대중적인 툴인 ArgoCD 를 기반으로 CI/ CD의 영역의 책임 분리, Spring 을 기반으로 하는 기술 스택의 재 활용 등을 수행했다.
- v2.1 : 진행 과정에서 알게된 제약 사항, 특히 온프레미스에서 수행하게 되다보니 발생한 리소스 경합, 네트워크 문제를 해결하는 구조를 포함한다. 또한 단일 실패지점(SPOF) 에 대한 구조적 한계점을 인지하고, Admin과 Service 의 구조적 설계를 보강한다.

특히 이러한 아키텍트를 하게된 목표는 다음과 같은 기준 때문이다.
- 3년차 개발 직군의 역량을 갖춰 보자! : k8s, Grafana, Loki, RabbitMQ(혹은 kafka)
- 현재의 표준화된 스케일링 도구들에 대한 이해도, 클라우드 플랫폼의 의존성을 탈피할 수단을 확실하게 배워 AWS, GCP, Azure 라는 굵직한 키워드 만큼이나, 기술 독립적인 역량을 갖추자
- AI를 서비스 개발, 서비스의 테스팅, 서비스 내부에 적극적으로 쏟아 넣어, 기계적으로 해결 어려운 문제를 해결하고, 생산성을 극대화 시키는 역량을 갖추자!
나의 목표는 그렇다. 이 프로젝트의 성공적인 런칭을 통해 사업을 하거나 하는건 당장은 힘드리라 생각한다. 그러나 몸의 회복을 하는 6개월의 시간을 이를 하면서 보냄으로서 다음을 철저히 준비하고, 무엇보다 ‘연차’나 ‘비개발직군’이 가지는 한계치를 뛰어넘는 역량을 증명해 내는 것. 그것이 본 프로젝트를 하는 목표의 한 축이라 할 수 있겠다. (물론, 위에서 언급한 불편함을 ‘나’에게 적용시켜서 스스로의 아쉬운 포인트를 긁어내고 싶은 점도 있긴 하다.)
디테일하게 아키텍처의 진화, 문제해결을 위한 구조 탐구
위에서 언급한 v1 ~ v2.1 은 내 목표를 달성하기 위한 ‘실전 구현’의 목표보다는 ‘기술검증’을 위한 도구에 가깝다. 실제로 n8n 을 테스팅 하면서 AI의 구축이나 서버의 구축은 사실 모놀리스식, 가장 빠르고 쉬운 접근법이 구현이란 차원에서 보면 맞을 수 있었다.
하지만 목표가 있기에, 그걸 위한 구조를 짜보면서 정말 많은 공부를 했기에 얻어낸 결실이었다.
최초 버전에서 한계점이 보였다. Java Spring 에 대한 작업을 안 해본건 아니지만, 너무 오래 되었기에 다시 보겠다는 점, 특히 WebFlux처럼 NestJS에선 당연한 도구지만 비동기, 비봉쇄의 이벤트 루프 방식의 처리를 통해 Java 진영 역시 빠르고 안정적인 단일 프로세스 기반의 비동기 처리가 가능해졌다. 이를 이해할 필요는 있어 보였다.
또한 k8s를 단순히 CLI로 쓰는 건 매우 어렵고 복잡한 일이었다. 특히 패키지 매니징을 통해 실무에서 검증된 기술을 쓴다는 점에서 생각하면 생성되는 수십개의 노드들의 관계나 디테일을 관리하기란 생각 이상으로 어려웠고, 이를 위한 도구가 ArgoCD라는 것을 이해했을 때, 도입과 함께 CD의 기틀을 GitOps로 가야 함을 깨달았다.
특히, 구조 상 폴리레포 형태를 포함해야하고, Git repo를 단일한 공급원으로 삼아 CI의 구성 효율화가 필요함, 원본 정보를 RAG 하기 전 상태로 유지해야 한다는 점등을 볼 때, MinIO의 필요성 등을 느꼈다.
특히나 가장 문제점은 홈랩(Homelab)을 구축하였고, 이를 기반으로 한 서비스 배포를 생각해보고 있는데, 공인 IP 한대로는 한개의 종단간 암호화 인증 및 서비스 배포가 되기 때문에, 간단히 생각해 443 포트를 가상 도메인 방식으로 Admin, Servce 모두 연결 시킬 순 있지만. 그렇게 했다간 Service 의 과부하 일 경우 Admin 접속이 불가능하다는 문제를 파악. 이를 개선하는 것을 포함하기 위해 GCP 프리티어의 인스턴스를 활용 L4 레이어 TLS passthrough 를 도입하는 등의 변화를 겪었다.
이러한 v2의 변화 이후엔, 더욱이 기존의 NextJS기반의 프론트엔드 작업, Jenkins 기반으로 먼저 올려두었던 프론트엔드 구축과 k8s 기반으로 동작한 백엔드 사의 문제점을 파악. 이를 고려한 통합 체계 구축이 필요했고, 특히나 최신 표전 Gateway API 사용이 필요하다는 점, 보안 운영 자동화 등을 고려하여 얻은 최종 결과 아키첵처가 v2.1 로 정리 되었다. 그리하여 간단하게 정리한, 그리고 각 구성은 다음과 같이 정리 된다.
v2.1 최종 아키텍처
| 저장소 | 역할 | 저장 데이터 | 위치 |
|---|---|---|---|
| PostgreSQL | 서비스 저장용, JSONB 기능으로 MongoDB 역할 포함 | A5 | |
| PostgreSQL - pgvector | AI를 위한 RAG 용 | A5 | |
| MinIO | ObjectStorage(S3호환) | 원본 파일 저장용, HTML 백업 등 | Centre |
- 개선 이유
- 현재의 온프레미스 상황에서 리소스의 분산은 효과적이지 못하고, 트래픽 대응에서 비효율적이다. (한 서버내에서 동작해야 하는 병목을 고려시)
- PostgreSQL 은 기본 VectorDB 기능을 포함하고 있기 때문에 RAG 데이터와 임베딩 벡터를 단일 트랜잭션으로 관리할 수 있게 되며, 이는 데이터 정합성, 일관성을 보장할 수 있게 만든다. 두개의 DB 를 별도 운영시 생기는 복잡한 동기화 문제를 원천적으로 제거하는 역할을 함.
- MinIO 는 RAG를 위한 원본데이터들의 보존, 외부 서비스(AWS 등)와 호환성 유지를 위한 도구로 사용함
- ORM
- NestJS (Prisma): 익숙한 스택으로 개발 속도 확보
- Spring (R2DBC): 새로운 논블로킹 스택 호환성을 위해, 기술 깊이 확보
- FastAPI (SQLModel): 파이썬 네이티브 스택으로 AI/RAG 연동성 확보
- MSA 서버 구성
| 서버명 | 주요 역할 | 내장 서비스 |
|---|---|---|
| Auth 서버 | 인증/인가, JWT 토큰 관리 | |
| User 서버 | 사용자 프로필 및 권한 관리 | • 기본 유저 서비스 • 별지기 서비스 • 샛별 서비스 |
| Chat 서버 | 대화 및 커리어 데이터 관리 | • Chat 서비스 • ActiveStatics 서비스 • Content 서비스 |
| AI 서버 | LLM 호출 및 RAG 처리, FastAPI 기반 | • RAG 서비스 • Crawling AI 서비스 (요약) |
| Noti 서버 | 알림 발송 | • Discord Webhook |
| Logging 서버 | 로그 수집 및 파일 저장 | • 내장 Message Queue • 파일 관리 |
| Schedule 서버 | 배치 작업 오케스트레이션 | |
| Psychological 서버 | 선행 서비스로, 심리 테스트 서비스 구현용 | - 답변 저장 - 답변 호출 - AI 서비스에 판단 요청 |
| API Gateway | 모든 통신의 출입구 역할. 가장 먼저 대응하는 서버 | |
| Redis 서버 | 캐싱 전략용 | |
| RabbitMQ | 메시지 전략용 서비스 | |
| Loki | stdout 로그를 수신하고, Grafana 로 전달 역할 |
서버별 책임 및 설계 결정
- API Gateway
- ==Spring Cloud Gateway==
- 모든 API 를 마주하는 공간. 여길 통해 접근이 되며, 최초의 트래픽의 대응 역할을 수행하여서 내부 서비스들을 보호하고 동시에 조절 관리한다.
- 특정 사용 제한 사항이 있다면, 이에 대한 조절, 통제 역할
- 서비스를 위한 전역 관리 사항들에 대해 통제하고, 문제 발생시 조절하는 브레이커 역할기(서비스들 보호 및 로직 단순화를 위한 용도)
- 기술 스택:
Auth 서버와 동일한 Spring WebFlux(논블로킹) 스택을 사용하여, v2 기술 목표(Spring 경험) 및 아키텍처 기술 일관성 확보. - 중앙 집중형 제어: 인증/인가, 사용량 제한(Rate Limiting), 서킷 브레이커(Circuit Breaker) 역할을 전담하여 백엔드 서비스들의 비즈니스 로직을 단순화.
- 성능 및 안정성: 비동기 논블로킹 스택으로 대규모 동시 트래픽을 효율적으로 처리하고, 장애 격리를 통해 시스템 전체 안정성 보장.
- Auth 서버
- ==Spring WebFlux + R2DBC==
- JWT 발급/검증, 리프레시 토큰 관리
- 다른 서비스와 분리하여 보안 계층 독립성 확보
- 기술 스택: v2 핵심 목표인 ‘Spring 비동기 논블로킹’ 스택 경험을 위해 선정.
- 도메인 적합성: 인증/인가는 I/O(DB 조회)가 잦지만 로직이 비교적 고립되어 있어, WebFlux의 성능 이점 테스트 및 새 스택 적용에 가장 안정적인 도메인.
- R2DBC: WebFlux의 논블로킹 철학을 DB까지 일관되게 유지하기 위해, 블로킹(Blocking) 방식의 JPA 대신 반응형(Reactive) DB 접근 기술인 R2DBC 채택.
- User 서버
- 통합 이유:
- 별지기/샛별은 역할(Role)이며 완전히 다른 도메인이 아님
- 하나의 계정이 두 역할을 동시 보유 가능 (샛별 = 별지기 + 샛별 기능)
- 초대 코드 기반 소규모 사용자로 병목 없음
- PostgreSQL 단일 트랜잭션으로 권한 변경 관리 단순화
-
권한 체계:
guest → 회원가입 → stargazer → 초대코드 입력 → protostar (질문 3회) (질문 10회/일) (모든 기능 사용)
- 통합 이유:
- Chat 서버
- Content 서비스 통합 이유:
- 초기 단계에서는 Content가 Chat 도메인과 밀접 (대화를 위한 자료)
- 장기적으로 비대해지면 독립 서버로 분리 가능하도록 모듈화
- 책임:
- 대화 저장/조회
- 질문 횟수 제한 체크
- 피드백 관리
- 통계 생성 (ActiveStatics)
- 커리어 데이터 업로드/관리 (Content)
- Content 서비스 통합 이유:
- AI 서버
- ==FastAPI 서버==
- Python 생태계가 LLM 통합에 유리
- Gemini API 사용으로 로컬 추론 부하 없음 (512MB-1GB 수준)
- Claude API로 전환 가능하도록 추상화 계층 구현 예정
- RabbitMQ 적용 (RAG 파이프라인):
Chat 서버의 파일 업로드(빠른 응답)와AI 서버의 임베딩 처리(느린 작업)를 비동기 큐로 완벽하게 분리(Decoupling). NestJS(Publisher)와 FastAPI(Consumer) 이종 스택 간의 안정적인 교차 통신 구현.
- ==FastAPI 서버==
- Noti 서버
- ==RabbitMQ== 적용으로 메시지를 구독하고, 각종 서비스에서 이벤트를 발행 이를 수신한다
- Dicord 알림이나, 이메일을 알림, 비밀번호 찾기 등의 보내기를 관리하는 서버
- RabbitMQ 적용 (이벤트 기반 디커플링): 타 서비스(Chat, User)가 발행(Publish)한 이벤트를 구독(Subscribe)하여 처리. 알림 API(Discord/Email)의 지연/장애가 원본 서비스에 영향을 주지 않도록 완벽히 격리.
- Logging 서버
- ==RabbitMQ== 적용으로 메시지르 구독하고 수신한다.
- 각 서버는 Logging 서비스에 로그 전송 후 무시 (fire-and-forget)
-
파일 저장이 핵심 역할 (장기 보관, 감사 로그)
- 이중화 전략:
- Loki (실시간 디버깅용): 각 서버
stdout(표준 출력)을 Loki가 수집, Grafana에서 실시간 스트리밍 및 필터링. (영구 보관 목적 아님) - RabbitMQ -> Files (영구 감사용): 서비스가 직접 발행하는 비즈니스 중요 로그(감사, 중요 에러)를 MQ를 통해 유실 없이 수신,
Logging 서버가 구독하여 파일로 영구 저장. (장기 보관 및 감사 추적 목적)각 서버 ├→ stdout (표준 출력) → Loki → Grafana (실시간 조회) └→ RabbitMQ 로 전달 -> Logging 서버 → Files (영구 보관)
- Loki (실시간 디버깅용): 각 서버
- Schedule 서버
- 오케스트레이터 역할 선택 이유:
- 배치 작업의 가시성과 제어권 중앙 집중화를 위한 전략
- “누가 언제 무엇을 실행하는가” 한눈에 파악 가능
- 각 서버는 비즈니스 로직을 소유, 스케줄만 Schedule 서버가 트리거
- 반복작업의 증대 및 복잡도 증가로 각 서버가 책임을 다해야할 시 해당 서버로 스케줄 이관 가능 (유연성 확보)
- 단 필요한 기능이 있을 때만 쓸 것이므로 일단 기획만 해줄 것
- 오케스트레이터 역할 선택 이유:
프론트엔드
- 프론트엔드 구성은 3가지로 구성됨
- 기술블로그에 올라가는 정적인 챗봇 컴포넌트
- 챗봇 컴포넌트에서 시작하여 SSR로 동작하는 챗봇 내부 UI 컴포넌트(SPA)
- 챗봇 설정을 위한 대시보드
- 미니 프로젝트(테스트 프로젝트)
- 심리 테스트를 AI 로 돌리는 것을 수행할 예정
- 간단한 UX 로 구현 + AI 이미지 에셋으로 완성시키기
- gpt-oss-120b 모델을 활용하여 API 사용 비용을 최소화 시킬 예정
- Big-Five 심리 테스트 방법론 + 판타지, SF 등을 활용해 재미있는 네러티브 테스트
- 회원가입 기능(간단 이메일, 알림 전달 용, 유저의 기록 저장및 검색용)
MSA 아키텍쳐 및 통신 방법
- k8s 를 사용하고, 내부에 대한 DNS 처리가 용이한 만큼, 내부에서 동작하는 DNS url 기반으로 동작하게 만들 것이다. 단 이때, 비동기적으로 동작해야 하는 경우, 혹은 FAF(Fire and Forget) 방식으로 마이크로 서비스로 전달해도 되는 것에 대해서는 RabbitMQ를 기반으로 하는 메시지 방식을 접목한다.
- 동기식 통신 (Synchronous): HTTP
- “질문/응답(Request/Response)” 방식의 통신으로, 요청자는 응답을 받을 때까지 기다린다. API Gateway, Auth 서버, User 서버 간의 정보 조회 등 즉각적인 응답이 필수적인 모든 곳에서 HTTP를 사용한다.
- 외부 진입 (External):
- 모든 외부 클라이언트 트래픽은
Host Nginx를 통해API Gateway로 진입한다. API Gateway는 인증/인가(Auth 서버호출), 사용량 제한 등 공통 정책을 중앙에서 처리한다.
- 모든 외부 클라이언트 트래픽은
- 내부 통신 (Internal):
- “정책 A: 내부 간 직접 호출 허용”을 채택한다.
- 서비스 간(예:
User 서버->Chat 서버)의 동기 호출은API Gateway를 거치지 않고, k8s 내부 네트워크(Service Discovery, 예:http://chat-service)를 통해 직접 통신한다. - 근거: 게이트웨이를 우회하여 내부 통신 성능(Low Latency)을 극대화하고,
API Gateway의 부하를 줄인다. - v2 경험: 이 정책은
User 서버와 같은 호출자(Caller)가Chat 서버의 장애에 대비한 서킷 브레이커(Circuit Breaker) 및 재시도(Retry) 로직을 직접 구현해야 함을 의미하며, 이는 v2의 핵심 경험 목표와 일치한다.
- 비동기식 통신 (Asynchronous): RabbitMQ
- “발행/구독(Publish/Subscribe)” 방식의 통신으로, 요청자는 작업을 “명령”하고 즉시 응답을 받는다(Fire-and-Forget). 서비스 간의 결합도를 완벽히 분리(Decoupling)하고 장애가 전파되는 것을 막기 위해 사용한다.
- RAG 처리 파이프라인 (교차 스택 통신):
- 흐름:
Chat 서버(NestJS) -> RabbitMQ ->AI 서버(FastAPI) - 목적: 사용자의 빠른 파일 업로드(HTTP 응답)와 시간이 오래 걸리는 AI 임베딩 처리(MQ 작업)를 완벽하게 분리한다.
- 흐름:
- 비동기 알림:
- 흐름:
Chat 서버/User 서버-> RabbitMQ ->Noti 서버 - 목적: Discord/Email 등 외부 API의 지연이나 장애가
Chat 서버와 같은 핵심 서비스에 영향을 주지 않도록 격리한다.
- 흐름:
- 영구/감사 로그 수집:
- 흐름: 모든 서비스 -> RabbitMQ ->
Logging 서버 - 목적: 실시간 디버깅용
stdout(Loki)과는 별개로, 비즈니스 중요 로그(감사, 중요 에러)를 유실 없이Logging 서버에 안정적으로 전달하여 영구 보관(Files)한다.
- 흐름: 모든 서비스 -> RabbitMQ ->
- k8s 관리 확정사항
- Kubernetes 배포판: MicroK8s
- A5(Main) 및 Centre(Sub) 서버의 Ubuntu 환경에 k8s 클러스터를 구축하기 위한 배포판으로 MicroK8s를 채택한다.
- 선택 근거:
microk8s enable <addon>명령어를 통해 Ingress, DNS, Prometheus 등 필수 애드온을 손쉽게 활성화할 수 있다.- k3s와 달리 etcd 등 표준 Kubernetes 컴포넌트를 거의 그대로 사용하여, 향후 EKS, GKE 등 매니지드 서비스로의 이전에 필요한 경험적 일관성을 확보하는 데 유리하다.
- 게이트웨이 전략: 이중(Dual) 게이트웨이
- 인프라 레벨과 애플리케이션 레벨의 게이트웨이를 명확히 분리하여, 각자의 역할에 집중하는 현대적 아키텍처를 구성한다.
- (1) 인프라 게이트웨이 (건물의 “정문”):
K8s Gateway API-ingress-nginx의 지원 종료(2026년 예정)에 대응하여, 차세대 표준인Gateway API를 도입한다. Nginx Gateway Fabric(NGF) 등Gateway API표준 구현체를 사용한다. - 역할: SSL/TLS 인증서 처리, 도메인/경로 기반 라우팅(예:api.my-domain.com->Spring Cloud Gateway) 등 클러스터의 “북-남(North-South)” 트래픽을 담당한다. - (2) 애플리케이션 게이트웨이 (건물의 “안내 데스크”):
Spring Cloud Gateway- V2 기획안의API Gateway서버 역할을 그대로 수행한다. - 역할: “정문”을 통과한 트래픽에 대해 JWT 인증/인가, 서비스별 사용량 제한(Rate Limiting), 서킷 브레이커, 비즈니스 로직 기반의 정교한 라우팅을 처리한다.
- 리포지토리 전략: GitOps를 위한 분리 모델
- CI(Jenkins)와 CD(ArgoCD)의 역할을 명확히 분리하기 위해 리포지토리 유형을 3가지로 표준화한다.
- (1) 템플릿 리포지토리 (
project-protostar-back)- 신규 마이크로서비스 생성 시 사용할 “설계 원본” 리포지토리이다.
- Spring, NestJS, FastAPI 등 스택별로 최적화된
Dockerfile템플릿과 공통.gitignore,.prettierrc설정 등을 보관한다. - 이 리포는 CI/CD가 감시하지 않으며, 오직 개발자가 새 서비스 레포 생성 시에만 참조한다.
- (2) 애플리케이션 소스 리포지토리 (App Repos)
- 명명 규칙:
project-protostar-{service-name}(예:project-protostar-auth-service) - 관리 방식: Polyrepo. 서비스별로 독립된 소스 코드 리포지토리를 가진다.
- 담당: Jenkins(CI)가 이 레포들을 감시한다.
- 구성: 실제 애플리케이션 소스 코드와, (1)번 템플릿에서 복사해 온 자신만의
Dockerfile을 포함한다.
- 명명 규칙:
- (3) K8s 설정 리포지토리 (Config Repo)
- 명명 규칙:
project-protostar-k8s-config - 관리 방식: Monorepo. k8s 클러스터의 모든 상태를 정의하는 단일 리포지토리이다.
- 담당: ArgoCD(CD)가 오직 이 리포지토리만 감시한다.
- 구성:
- 모든 App Repo 서비스의
Deployment,Service,HTTPRouteYAML. - k8s 클러스터 내부에 배포될 인프라(PostgreSQL, RabbitMQ, Redis)의 YAML .
- 모든 App Repo 서비스의
- 제외: Centre 서버에서 별도 운영되는
MinIO관련 설정은 이 리포지토리에서 제외한다.
- 명명 규칙:
- CI/CD 자동화 워크플로우
- (1) CI (Jenkins):
App Repo의 코드 변경을 감지 ->Dockerfile을 이용해 빌드 및 컨테이너 이미지 푸시 ->Config Repo를clone하여 해당 서비스의Deployment.yaml내 이미지 태그를 새 버전으로 수정한 뒤commit&push한다. - (2) CD (ArgoCD):
Config Repo의 변경 사항(Jenkins가 푸시한 커밋)을 감지(OutOfSync) -> k8s 클러스터로 변경 사항을pull하여 배포(Sync)를 자동 수행한다.
- (1) CI (Jenkins):
- Kubernetes 배포판: MicroK8s
혼자서, 그리고 왜?

2023년 300명 규모의 개발자 커뮤니티 행사 WASSSUP 당시, 실무진으로…

Peer 개발 총괄로 MT

Peer 개발 프로젝트가 처음인 신입들을 위한 Final Mission 행사

gemgem theraputics 팀 , 사업 확장 차 뉴욕 방문 당시
3년 간 개발자로 살면서 정말 많은 일들이 있었다. 42서울에서는 동료 학습을 배웠고, 정신이 없었다. 그러는 와중에도 Peer라는 귀한 이들을 만나, 개발자 다운 성장, 프로젝트의 어려움을 해결해보려고 노력했다. 그 과정에서 행사도 만들어보고, 개발도 해보고, 기획과 리딩도 해보면서 정말 많은 일들을 했고, 그 마지막에 1년이란 시간을 gemgem theraputics 에서 성장할 수 있는 기회를 얻었다.
다소 아쉬움도 있었다. 몸 건강을 잘 유지하지 못하고 고무줄 처럼 늘어난 몸무게(…)는 쉽지 않았고, 현재는 약 20kg 정도 감량하고, 더 감량하면서 이 프로젝트를 하고 있다.
누군가는 이렇게 이야기 했다. 돈 벌고, 모은 돈 써가며 왜 시간을 쓰냐. 그냥 이직해도 되지 않냐? 더 공부할 필요 뭐 있냐. 하면서 배우면 되지.
음, 틀린 말은 아니라고 생각한다. 하지만 나의 인생, 많은 실패 속에서 얻어온 것들을 기반으로 얻은 내 생각은 조금, 다소 다르다.
돈도 중요하고, 경험도 중요하다. 무엇보다 중요한건 시대가 뭘 필요시 하냐? 에 대해 제대로 물을 줄 아는 태도와 제대로 답할 줄 아는 태도가 아닐까 싶다. AI가 등장하고 정말 편리한 개발이 되게 되었고, 개발 뿐 아니라 모든 영역이 그렇게가 가능해졌다. 하지만 그 결과 우리는 이제 엄청난 기술격차와 싸우게 되었고, 또 반대 급부로 어지간한 일은 다 할 수 있게 되었다.
문제는 도구를 어떻게 쓰냐, 어떤 철학, 방법론을 알고 있냐에 따라 AI 를 부리는 사람으로 평가 받을 수도 있고, 반대로 AI에게 부림 받는 경우를 맞이할 지도 모르겠다.
그러다보니 몸이 아프고, 쉼이 필요한 시점이자 동시에 이 프로젝트를 고안하고, 스스로의 힘으로 해결해보려고 하는 것은. 어쩌면 지금 나의 시대를 주체적으로 준비하고, 제대로 돈도 벌고, 제대로 기회도 얻고, 제대로 전문가의 그 길 위에 서기 위한 준비의 기간이라고, 자기 투자의 기간이라고 나는 생각한다.
그러니 1년 차지만, 3년차를 목표로 생각하며, 3년차는 경험하지 못할 AI의 가속도를 경험하고 싶다. 그것이 어쩌면 솔직한 내 상황이리라 싶다.
결론, 지평선 넘어를 보기 위해
기술적 복잡도, 기술적 구현해야할 양 많은 것이 사실이다. 몰입해야 하고, 시간을 미친듯이 쏟아 넣고 있다. Obsidian에 온갖 AI 기반 프롬프트로 문제를 해결해나가고, n8n 기반으로 자동화된 소식통을 통해 현재의 ai 트랜드, 기술의 발전 경향을 탐독하고 있다.
Protostar는 만나는 구조적 문제들에 밤을 새어가면서 만들고 있는데, 덕분에 건강 챙기기는 약간 딜레이(?) 가 생여 신경 써야할 것 같다.
하지만 언덕 넘어를 보고 싶다는 마음 하나는 명확하다. Project Protostar는 이를 위한 한계를 뛰어넘는 발판이 되도록 만들고 싶으며, 만들고난 뒤엔 클로즈 테스트, 만약 잘되면 지속적인 서비스로 조그맣게 운영해볼 마음도 있다.
달리자.