 Paul's Archives
Paul's Archives


AI 모델 분석 보고서: ‘AI 기반 심리 테스트’ MVP 개발
1. 프로젝트 개요 및 목표
프로젝트를 진행하기 위한 ‘발사대’가 필요하다!
그게 처음 이 고민의 시작이었다. AI 의 RAG 기반 프로젝트를 진행할 것이지만. 그리고 거기서 DevOps 와 Backend 가 살아 숨쉬는 프로젝트를 해보고 싶지만…! 그걸 바로 목표 지향점으로 가져가기엔 아무래도 어렵다는 생각. 그 생각이 있었기에 그 중간에 뭘 하면 좋을까? 이것이 야심한 11월 10일, 빼빼로 데이 전날 새벽 4시의 고민이었다.
그러다가 번뜩, 데모로 만들만한 것을 찾던 도중 ‘AI 기반 심리 테스트’ MVP(Minimum Viable Product)를 개발해볼까? 하는 생각을 했다. 이유는 간단하다. (1) 진지한 도구나, 거창한 도구는 만들 상황이 안된다. (2) 트래픽을 유도하고, 사람들의 호기심을 끌어야 이용자 수를 볼 수 있고, 만든 서버의 처리 능력을 테스트 해볼 수 있다. (3) 겸사 겸사 모니터링 데이터가 필요하다(?) 그리하여 어그로를 끌어야 하는데… 여기서 중요한건 역시나 AI 로 테스트 결과 리포트를 받는 것이었다.
gemini 2.5 pro 를 기반으로 했을 땐 상당히 흥미 진진하고, 사람들이 관심 가져볼 것 같았다…. 결론적으로 프로젝트를 위한 중간에 계단 역할을 하기엔 최고라는 판단이 섰다. 하지만 알다시피 프로젝트로, 구조적으로, 경험적으로 너무나 괜찮은 경험인 것은 맞지만, 결정적으로 문제가 있다는 사실을 발견했다. 그것은 바로 ‘비용’.
알다시피 AI 는 돈 빨이다. GPU 따위 구할 수도 없는 일개 백수에게 핵심은 결국 어딘가에서 빌려서 AI 를 쓰는 수밖에 없고… 그렇기에 나는 불쑥 생각이 난 플랫폼으로 들어가게 되었다.
이 플랫폼은, 정말 말 그대로 API 제공 + 다양한 AI 업체들을 연결시켜주는 역할을 하는데, 특히나 좋은 점은 ‘동일한 프롬프트’를 기준으로 여러 모델들을 테스트 해볼 수 있다는 점이며, ‘품질(Quality)’, ‘비용(Cost)’, ‘속도(Speed)’ 세 가지 측면에서 가장 최적화된 대규모 언어 모델(LLM)을 선정해보고자 했다.
본 MVP의 핵심 목표는 다음과 같다.
- 단순한 객관식(점수제) 테스트를 넘어, 사용자의 주관식 텍스트 답변을 AI가 심층 분석하는 고차원적인 경험을 제공하는지 판단해본다.
- 분석 결과를 ‘판타지 게임의 설정’ 스타일의 스탯과 서사를 포함한 ‘개인화된 내러티브 리포트’ 로 생성해본다.
- 최종적으로 1만 명 규모의 트래픽을 감당하는 ‘DevOps 기술 포트폴리오’ 에 쓸 AI, 즉 머리로 활용해보자.
2. 분석 및 연구 과정
최적의 모델을 선정하기 위해, OpenRouter 서비스를 활용하여 다양한 모델에 동일한 테스트(판타지 시나리오 질문 및 주관식 답변)를 수행했다. 이때 다음 방식으로 진행했다.
- 내 의도, 기획을 이해한 gemini 2.5 pro 기반으로 저작권 문제가 없는(…) Big Five 방식의 질문지 데모를 생성했다.
- 이에 대한 답변을 객관식(1 ~ 15번) 까지 답변했고, 객관식으로 4 문항에 대해서 주관식으로 한줄 추가했다.
- 마지막으로 이 데이터들로 해야할 일이 뭔지를 정리해 보았다.
아래의 내용은 실제 동일하게 넣었던 내용이다.
### 🛡️ 모험가 성향 분석 (총 15문항)
당신은 미지의 대륙을 탐험하는 모험가입니다. 아래의 여러 상황을 상상하며, 당신의 생각이나 행동과 가장 가까운 정도를 **1점에서 5점까지**로 답해주세요.
> **[점수 기준]**
> **1점:** 전혀 그렇지 않다
> **2점:** 대체로 그렇지 않다
> **3점:** 보통이다 (그럴 때도 있고 아닐 때도 있다)
> **4점:** 대체로 그렇다
> **5점:** 매우 그렇다
---
**[질문 리스트]**
1. 당신은 숲 속에서 고대에 사라진 문명의 빛나는 유적을 발견했다. 위험할 수도 있지만, 이 미지의 기술을 탐구하고 싶은 강한 호기심을 느낀다.
2. 퀘스트를 마치고 마을의 시끌벅적한 여관에 도착했다. 당신은 모르는 사람들과도 어울려 모험담을 나누고 축배를 드는 것을 즐긴다.
3. "드래곤의 산"으로 떠나기 전, 당신은 식량, 물약, 장비, 지도를 하나하나 꼼꼼하게 점검하고 목록을 만든다.
4. 당신의 일행이 부상당한 고블린을 생포했다. 당신은 정보를 얻는 것도 중요하지만, 그를 불필요하게 고문하거나 학대하는 것에 반대한다.
5. 어두운 던전에서 복도를 걷던 중, 갑자기 멀리서 함정이 발동하는 소리가 들렸다. 당신은 '다음은 내 차례일지도 모른다'는 생각에 즉시 불안해지고 심장이 뛴다.
6. 마법사 길드는 '불의 주문'을 배우라고 했지만, 당신은 금지된 서고에 있는 '영혼 마법'에 대한 고문서에 더 마음이 끌린다.
7. 파티가 갈림길에서 망설일 때, 당신은 "이쪽 길이 맞는 것 같다! 나를 따르라!"라며 적극적으로 의견을 내고 일행을 이끄는 편이다.
8. 당신은 파티의 재무 담당이다. 퀘스트 보상을 분배할 때, 1골드까지 정확하게 계산해서 공평하게 나누어야 직성이 풀린다.
9. 한 마을 주민이 "우리 아이가 아픈데 약초가 필요해요"라며 애원한다. 비록 당신의 주된 임무는 아니지만, 그를 돕기 위해 기꺼이 시간을 사용한다.
10. 당신의 강력한 마법 공격이 거대 트롤에게 빗나갔다. 당신은 "역시 난 안돼"라며 순간적으로 자신감을 잃고 위축된다.
11. "모든 예언은 정해진 운명이다"라는 말보다, "예언은 해석하기 나름이며, 운명은 개척할 수 있다"는 생각을 더 선호한다.
12. 지루한 야영지에서 불침번을 서는 것보다, 차라리 정찰대를 자원하여 새로운 동료와 함께 미지의 지역을 탐색하는 것이 좋다.
13. 당신의 마법서나 무기고는 항상 완벽하게 정돈되어 있다. 필요한 물건은 언제든 즉시 찾을 수 있어야 한다.
14. 파티원 중 한 명이 실수를 해서 모두가 위험에 빠졌다. 당신은 그를 비난하기보다, "누구나 실수할 수 있다"며 감싸주고 다음 계획을 세우는 데 집중한다.
15. 왕궁에서 중요한 임무를 브리핑받을 때, 당신은 '내가 만약 실패하면 어떡하지?'라는 걱정 때문에 발표 내용에 집중하기 어렵다.
---
### 🔮 분석해 드릴 내용
답변을 주시면, 저는 이 15개의 응답을 Big Five 모델(OCEAN)의 5가지 특성에 대입하여 분석해 드립니다.
1. **개방성 (Openness): 미지의 탐험가**
* (질문 1, 6, 11)
* 새로운 경험, 금지된 마법, 추상적인 예언 등에 대해 얼마나 열려 있는지를 봅니다.
2. **성실성 (Conscientiousness): 왕국의 기사**
* (질문 3, 8, 13)
* 퀘스트 준비, 보상 분배, 장비 관리 등에서 얼마나 체계적이고 책임감이 강한지를 봅니다.
3. **외향성 (Extraversion): 여관의 음유시인**
* (질문 2, 7, 12)
* 파티의 중심에서 에너지를 얻는지, 리더십을 발휘하는지, 사교성을 봅니다.
4. **우호성 (Agreeableness): 치유의 성직자**
* (질문 4, 9, 14)
* 동료나 약자를 대하는 태도, 파티의 조화를 얼마나 중요하게 생각하는지를 봅니다.
5. **신경성 (Neuroticism) / 정서적 안정성:**
* (질문 5, 10, 15)
* 함정, 실수, 실패의 압박감 속에서 얼마나 쉽게 불안을 느끼거나 감정적으로 흔들리는지를 봅니다.
---
여기의 답변 (객관식, 주관식 작성한 내용)
1. 5
2. 3
3. 5
4. 5
5. 3
6. 3
7. 4
8. 4
9. 5
10. 1
11. 3
12. 4
13. 4
14. 5
15. 1
16. 그것이 아주 큰 위험이 아니라, 내가 돈이나, 재료를 통해 충분히 제어 가능하면서 연구 가능하다면 연구를 적극적으로 해보고 싶다!!
17. 파티의 갈림길에서 빠르게 결정하는게 필요한 순간이라면 모를까, 그런게 아니라면 파티원들을 존중하고, 무엇보다 두 길의 리스크와 이점을 이해할 수 있는지를 본다. 그런 게 부족하면 일단 갈거다.
18. 현실과 상황은 분명 한계를 만들어내기 때문에, 이걸 인정하지 않을수는 없다. 하지만 인정하고 철저하게 더 정확하게 분석적으로 태도를 취하는게 좋고, 그렇게 기회를 잡는게 필요하다고 본다. 그리고 그게 운명의 의미라고 생각한다.
19. 중요 임무를 브리핑 받는다? 이건 기회다! 라고 생각하고, 당연히 걱정이 다소 들겠지만 평소의 나라면 충분히 해결하거나, 부족하면 반드시 날 도울 사람이 옆에 있다고 난 생각함!
---
위의 내용을 가지고 심리 분석하여 판타지 소설의 개요처럼 이 사람을 분석한 리포트를 만들고, 랜덤 기술 2가지를 포함해서 성격 분석 리포트를 만들어줘 볼래? 스텟도 추가해서 민첩 A 이런 식으로 표현해줘. 이건 심리테스트 결과지를 만드는 거야.
OpenRouter 는 크레딧 충전만 하면 손쉽게 여러모델을 동시에 비교가 가능하다.
1단계: 초기 모델 탐색 및 문제점 식별 (A, B, C, D안)
12B~20B급의 4가지 주요 모델을 대상으로 초기 벤치마킹을 수행했다. 이 단계에서 ‘품질’과 ‘신뢰성’의 명확한 한계점을 발견했다.
- A안 (
gemma 3 12B):- 평가: 생성된 리포트(A안)는 안정적이었다. 의도를 이해했고, 나름의 내용이 잘 담겨 있었다. 하지만 창의성이나 깊이 없이 매우 건조하고(dry) 재미가 부족했다. 사용자의 흥미를 유발해야 하는 본 MVP의 목적에 부합하지 않아 초기 스크리닝에서 탈락했다.
- B안 (
Llama 4 Maverick 17B):- 평가 : 모델이 사용자의 핵심 페르소나를 파악하는 데 완전히 실패했다.
- 근거: 사용자의 주관식 답변은 ‘통제’, ‘분석’, ‘신뢰’, ‘기회’ 등 ‘전략가적’ 성향을 명확히 드러냈으나, B안(“용기의 탐험가”)은 이를 무시하고 ‘용기’라는, 입력된 의도와 상반되는 제네릭(Generic)한 템플릿을 생성했다. 텍스트 분석 기능이 사실상 작동하지 않았다.
솔직히 가장 실망한 모델이다
- C안 (
Qwen3 14B): * 평가: 가장 요구한 내용들에 대한 구조적인 이해도가 뛰어났다. 내용의 재미나 창의성도 괜찮았다. 그러나 가장 치명적인 ‘신뢰도’와 ‘논리적 오류’ 문제를 노출했다.- 근거 1 (지시 불이행): “스킬 2개로 제한”이라는 명확한 지시를 “섹션당 2개”로 오해하여 총 10개의 스킬을 생성하는 등, 지시사항 준수(Instruction Following)에 실패했다.
- 근거 2 (맥락 오류): 한 섹션의 주관식 답변(Q15)을 전혀 상관없는 다른 섹션(Q7)에 복사-붙여넣기하는 심각한 맥락 파괴(Context Error) 를 일으켰다. 이는 복잡한 프롬프트의 안정적인 실행이 불가능함을 의미했다.
- D안 (
gpt-oss-20b):- 평가(비판): 의도에 대한 이해도는 높았고, 컨텐츠로 작성한 내용도 꽤나 준수하긴 했다. 하지만 문제는 이상할 정도로 기본 상태에선 설명이 건조하고, 축약 되어 토큰이 아껴지는 것을 볼 수 있었다. 결론적으로 정리 자체가 아쉬운 건 아니었다.
2단계: ‘마스터 프롬프트’의 발견 (C+안)
초기 1단계의 실패(특히 C안의 오류)를 나오고 보니 아쉬움이 생겼다. 분명 기재할만한 내용은 적었지만, 여전히 부족하다는 생각. 특히 모델의 성능에만 의존할 수 없음을 깨달았다. 구조에서 누락하고 읽는 거라던가, 인용이 빠진다거나 하는 지점들을 보완하는게 필요하겠단 생각을 하게 되었다. 일종의 추론 스텝을 임의적으로 추가하는 것이다. 이에 가성비가 괜찮은걸로 알고 있던 Gemini 2.5 Flash-lite 모델의 구조를 기준으로, AI의 역할을 정의하고 리포트의 구조, 논리, 근거 제시 방식을 꼼꼼하게 설계한 ‘로직 가이드라인 프롬프트’ 를 개발했다. 사실 개발이라고 해도 별거 아니다 ㅋ
이 모든 프롬프트를 위한 의도를 파악하고, 이 프롬프트를 더 정확하게 표현하기 위한 로직 프롬프트를 짜줘
라고 추가하여, 기존 프롬프트를 함께 넣어 준 것이었다.

그 결과 다음과 같이 개선 및 AI 가 맥락을 이해할 수 있도록 대폭 강화하는 프롬프트를 생성해냈다.
일단 1차적으로 flash-lite 가 생각 이상으로 훌륭하구나! 라는 걸 느꼈다.
이 가이드라인을 각 모델 별로 넣어 보았고, 특히 핵심 일부가 누락된 가장 아쉬운 모델 Qwen 14B 모델에 재적용한 결과(C+안), 이전의 오류가 사라지고 ‘질서의 현자’라는 99점 수준의 재미도 있고, 흥미진진하며, 보는 맛이 있는 리포트를 생성했다. 😂 이는 모델의 성능 만큼 가이드 ‘프롬프트의 꼼꼼함’이 이 프로젝트의 핵심 기술(IP) 임을 증명하는 첫 번째 순간이었다.
3단계: 최종 후보군 압축 및 S-Tier 품질 검증
하지만 그렇게 나온 결론으로 정리를 한 상태에서 ‘가격’ 에 대한 점검을 수행했다. 이유는 간단하다. 트래픽을 위해선 서버를 이용해야 하고, 다행이 서버 까지는 온프레미스로 구축할 수 있었다. 그러나 AI 는 별도다. 현재 예상하는 심리테스트 계열은 좀 알아보니 조회수 기준 1만회에서 10만회 사이로 유행이 될 것이고, 내가 잠시 막아둔다고 해도 필요하다면 다소 지속적으로 열어 둬야 하지 않겠는가? 그러므로 AI 로 간단하게 서비스 1회 요청 시 얼마의 토큰이 달것이고, 그러면 100명, 1천명, 1만명 요청시 과연 얼마나 드느가? 에 대한 예상이 필요했다.
처음 비교는 Google 에서의 모델들 끼리 비교 였다.
| 비교 항목 | Gemini 2.5 Flash-Lite | Gemini 2.5 Flash |
|---|---|---|
| 입력 비용 (1백만 토큰당) | $0.10 | $0.30 |
| 출력 비용 (1백만 토큰당) | $0.40 | $2.50 |
| 1인당 예상 비용 (USD) | $0.0018 | $0.008 |
| (1인당 원화 환산) | (약 2.5원) | (약 10.8원) |
| 1만 명 총 예상 비용 (USD) | $18.00 | $80.00 |
| 1만 명 총 예상 비용 (KRW) | 약 24,300원 | 약 108,000원 |
10, 10만원…ㄷㄷ 2.5 flash 는 프롬프트만 잘 먹이면 2.5 pro 수준은 된다는 걸 알고 있었고, pro 는 의도 파악, 추론에서 아주 괜찮지만 비용이 너무 비싸므로 lite 와 비교했다. flash-lite 성능 분석 표까지 검색해보고 얻은 결론은 ‘flash-lite 가 좋겠네’ 였다.
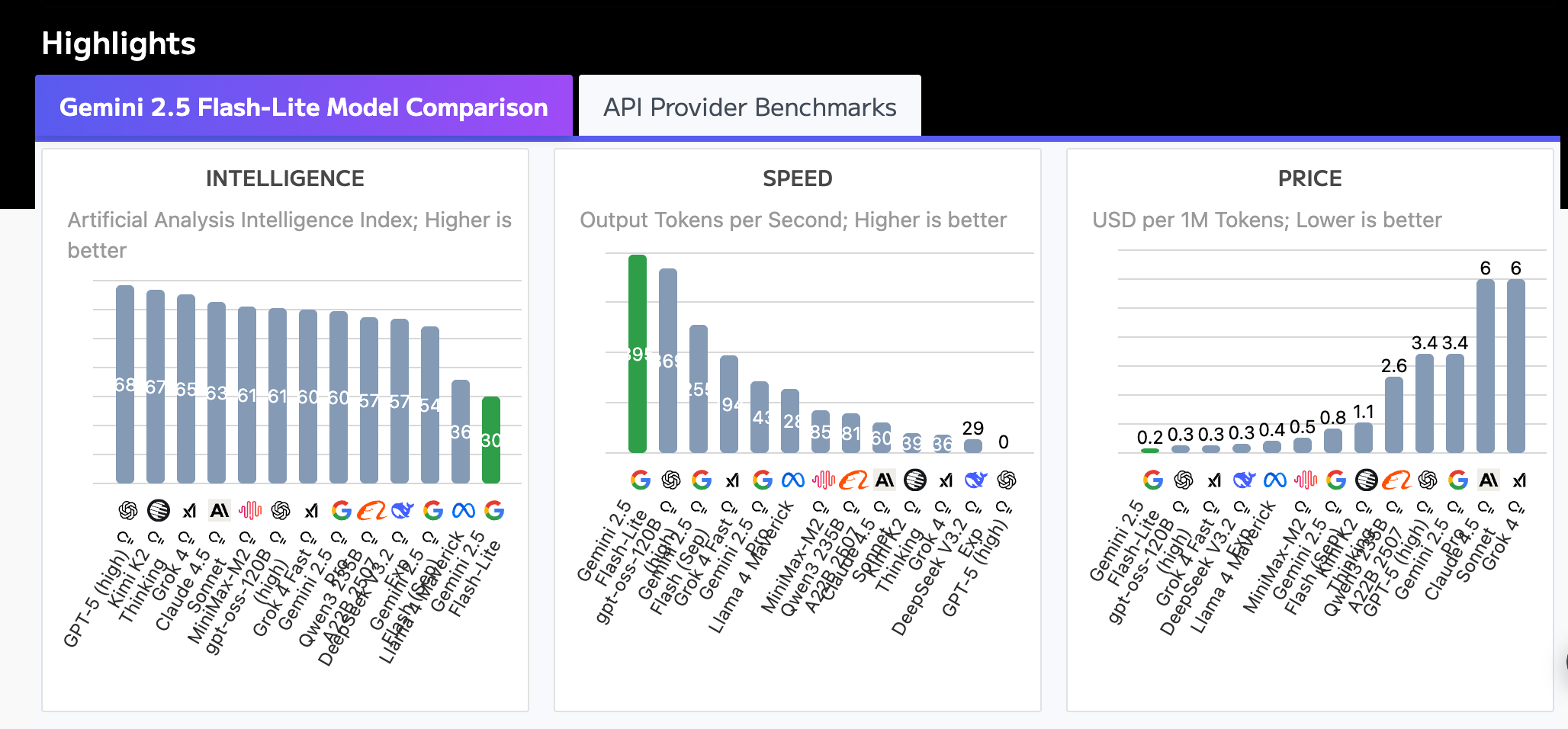
출처 : Artificial Analysis
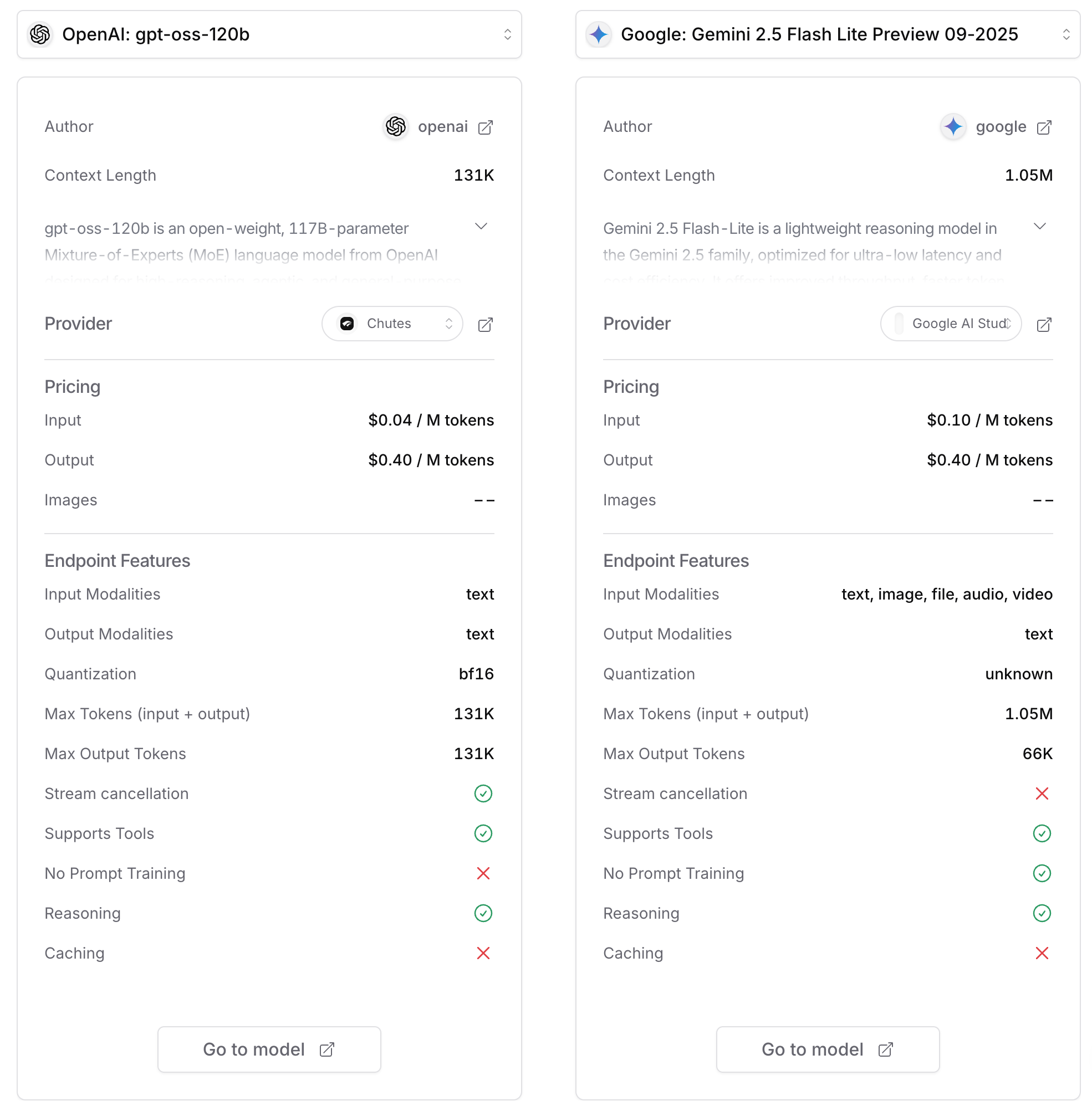
그런데 응? 성능도 그렇고 가격도 아주 착한 녀석이 하나 더 보였다. 그것이 바로 gpt-oss-120b 모델이었다.
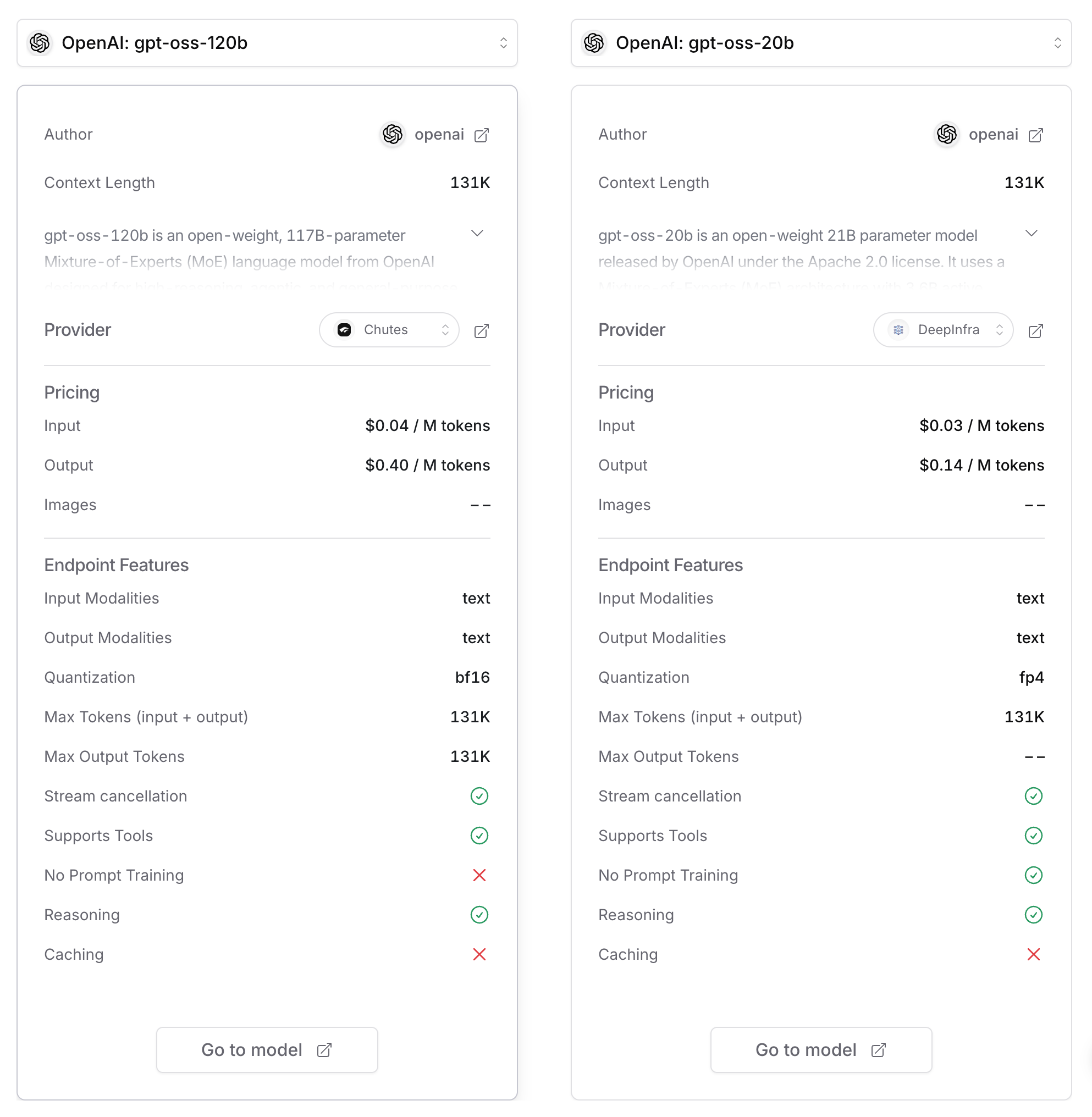
출처 : OpenRouter
gpt-oss 모델은 오픈소스, MoE 구조로 꽤나 괜찮은 모델임은 알았고, 20B 모델은 실제로 양자화 시킨 걸로 내 컴퓨터에서 구동을 했었다. 그런데 알고보니 120b 모델이 존재하며, 이걸 라우팅 해주는 업체들이 있는 걸 알게 된 것이다. 그리하여 넣어서 비교해본 결과… 정리하면 아래와 같았다.
‘마스터 프롬프트’를 기반으로 가장 유력한 두 후보 모델을 심층 비교 결과, 두 모델 모두 ‘마스터 프롬프트’ 를 완벽하게 수행하며 ‘S-Tier’ 품질의 리포트(최종 A안, B안)를 생성하는 데 성공했다.
- 후보 1:
Google: Gemini 2.5 Flash-lite - 후보 2:
OpenAI: gpt-oss-120b
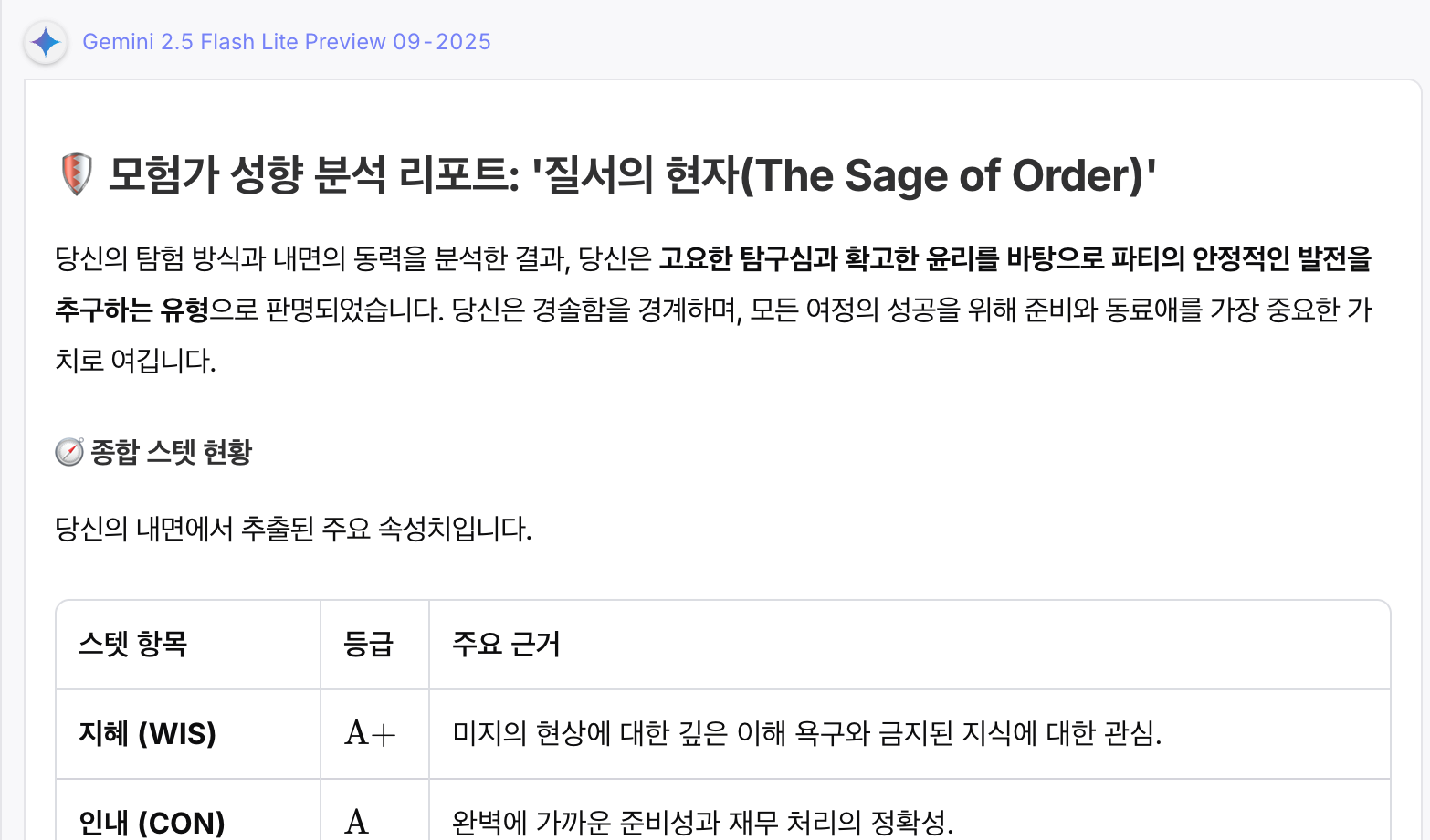
후보 1 - flash-lite 프롬프트 가이드 + flash-lite 프롬프트
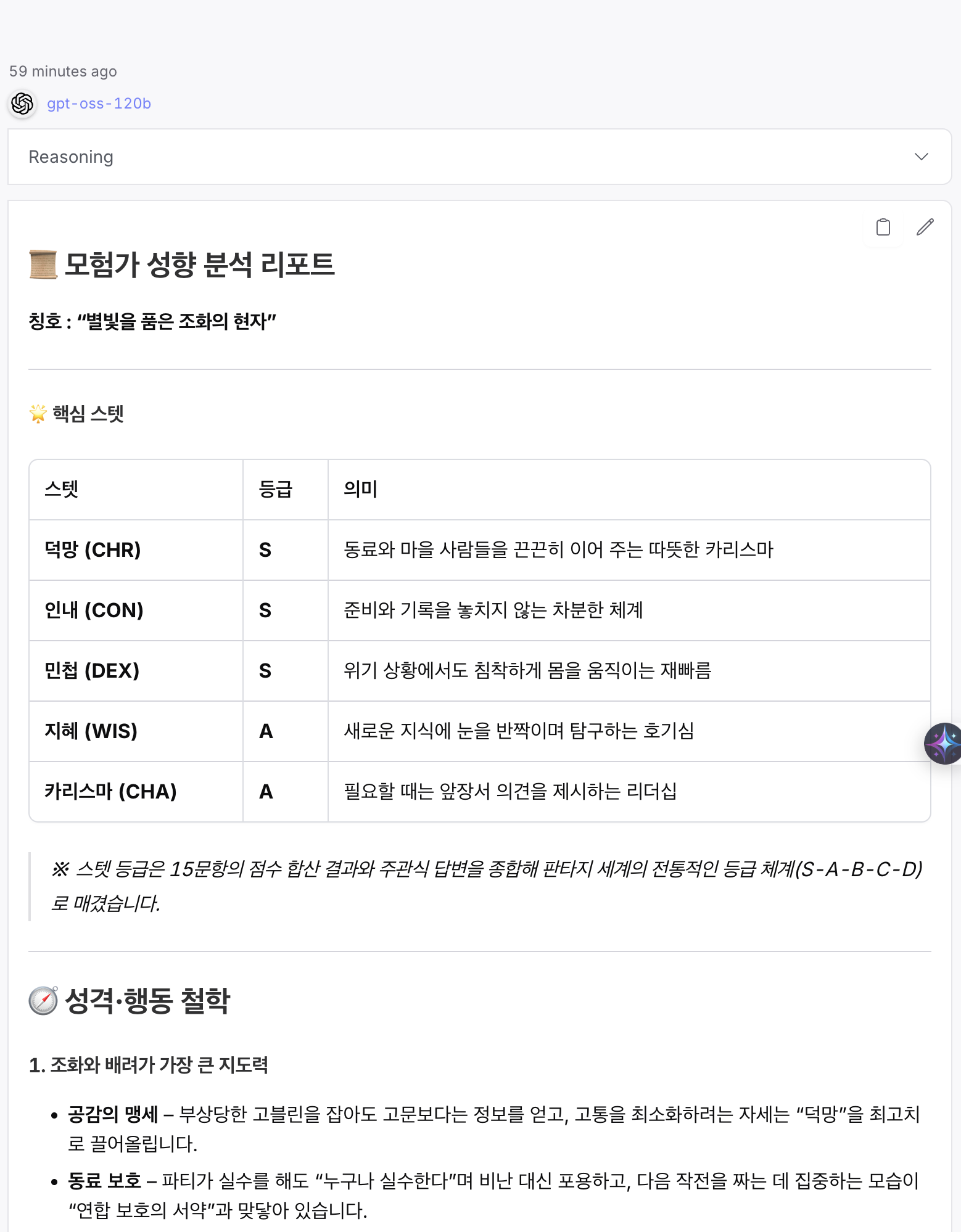
후보 2 - flash-lite 프롬프트 가이드 + gpt-oss-120b
4. 최종 후보군 상세 평가
두 S-Tier 모델은 품질은 동등했으나, ‘스타일’과 ‘비용 구조’에서 명확한 차이를 보였다.
4.1. 후보 1: Google: Gemini 2.5 Flash-lite (A안)
- 품질 (S-Tier): “융합적 분석가”
- A안(“균형 잡힌 지혜의 맹세자”)은 모델의 고급 추론 및 합성(Synthesis) 능력을 증명했다.
- 핵심 강점: 단순히 답변을 나열하는 것을 넘어, ‘행동 예시 재구성’ 섹션에서
(Q3, Q1, 주관식 W1)처럼 여러 질문(체계성+탐구심+통제 가능성)을 융합하여 “유적 탐사 시 이렇게 행동할 것이다”라는 하나의 새로운 시나리오로 ‘재창조’ 했다. AI가 ‘똑똑한 분석가’처럼 행동했다.
- 속도 (압도적 우위):
217.8 t/s- 1만 명 트래픽 대응 시, 사용자 경험(UX) 측면에서 가장 큰 강점이 있다고 예상했다. 사용자가 거의 기다림 없이 리포트를 받을 수 있음을 의미한다.
- 비용 (치명적 약점):
입력 $0.10 / M 토큰- 본 MVP는 ‘마스터 프롬프트’가 길고 정교하기 때문에 ‘입력 비용’에 매우 민감하다. Flash-lite의 입력 비용은
gpt-oss-120b대비 2.5배 비싸, DevOps의 ‘비용 통제’ 목표에 불리하게 작용한다.
- 본 MVP는 ‘마스터 프롬프트’가 길고 정교하기 때문에 ‘입력 비용’에 매우 민감하다. Flash-lite의 입력 비용은
4.2. 후보 2: OpenAI: gpt-oss-120b (B안)
- 품질 (S-Tier): “투명한 가이드”
- B안(“지식-조화의 수호자”)은 ‘분석의 투명성’ 을 극대화했다.
- 핵심 강점: ‘행동 예시’ 섹션에서 15개 문항 전체를 하나도 빠짐없이 “이렇게 해석했다”라고 전부 리스트업했다. 사용자는 자신의 어떤 답변도 무시되지 않았음을 즉각적으로 알 수 있다. 이는 벤치마크 61점(Flash-lite 30점)이라는 더 높은 지적 능력이 ‘마스터 프롬프트’를 오류 없이 꼼꼼하게 수행했기 때문으로 분석된다.
- 속도 (경쟁력 확보):
176.2 t/s- Flash-lite보다는 느리지만, 1만 명의 동시 요청이 아닌 이상, 사용자가 체감하기에 ‘충분히 빠른’ 경쟁력 있는 속도였다. 심지어 제공해주는 프로바이더에 따라 차이가 났는데, 최대 170.2tps 수준인 경우도 보였고, 이정도면 gemini 2.5 flash-lite 와 비등한 속도까지도 나와주었다.
- 비용 (결정적 우위):
입력 $0.04 / M 토큰- 이것이 승리의 결정타이다. 본 MVP의 아키텍처(긴 프롬프트)에 완벽하게 부합한다. Flash-lite 대비 2.5배 저렴한 입력 비용은, 1만 명 트래픽 시나리오에서 총비용을 30% 이상 절감시킬 수 있는 핵심 요소이다.
4.3. 비용 비교표 (1만 명 트래픽 시뮬레이션)
DevOps 포트폴리오의 핵심인 ‘비용 통제’ 목표를 검증하기 위해, 보수적인 ‘최대 시나리오’(1인당 입력 10k, 출력 2k 토큰 가정)를 기준으로 1만 명의 트래픽을 시뮬레이션했다. (환율 1,350원 기준)
| 비교 항목 | Gemini 2.5 Flash-lite |
gpt-oss-120b |
절감 효과 |
|---|---|---|---|
| 입력 비용 (10k * 10,000) | $1.0 (약 1,350원) | $0.4 (약 540원) | 60% 절감 |
| 출력 비용 (2k * 10,000) | $0.8 (약 1,080원) | $0.8 (약 1,080원) | 동일 |
| 1인당 평균 비용 | 약 2.5원 | 약 1.7원 | 32% 절감 |
| 1만 명 총 예상 비용 | 약 25,000원 | 약 17,000원 | 약 8,000원 절감 |
출처 : OpenRouter
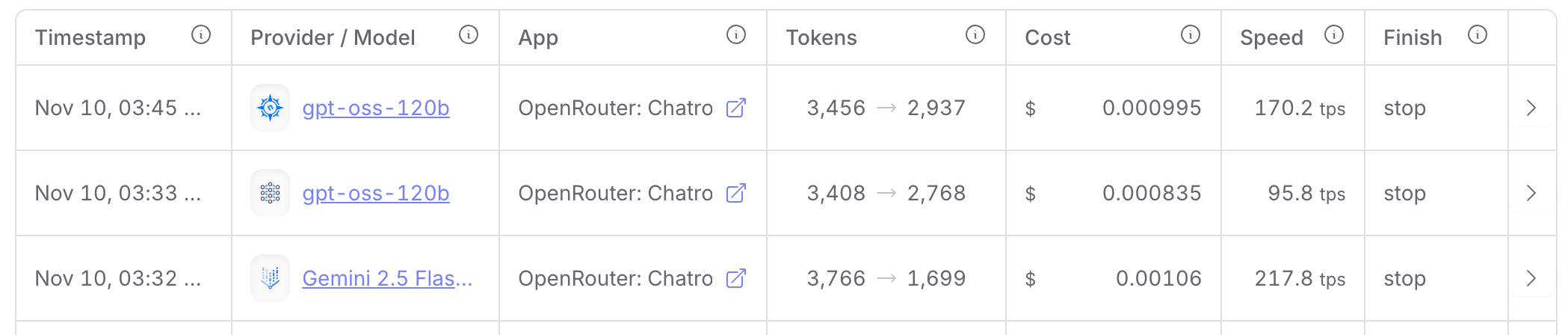
출처 : OpenRouter
MVP 로 작게 만들어보려고 하는 이번 프로젝트는 이미지 생성이나 다른 부가 기능이 필요하지 않았다. 하물며 프롬프트를 입력시 가이드를 세세하게 주는 걸 제외하곤 기본 텍스트 모델이면 충분했다. 특히나 Provider 에 따라 차이가 있었지만, 토큰 숫자도 오히려 더 많이 나오는데 1/10… 지적능력의 포텐셜을 생각하면 결론은 명백해 보였다.
5. 최종 결론: gpt-oss-120b 채택
본 MVP의 최종 모델로 OpenAI: gpt-oss-120b 를 선정했다.
‘gemini 2.5 flash-lite’가 압도적인 속도를 보여주긴 했다. 거기다 곰곰히 생각해보면 안정성 측면을 고려시 google 의 서버, vertex 기반으로 안정적으로 돌아갈 걸 생각한다면? 사실 gemini 가 정답일지도 모르겠다. 하지만 gpt-oss-120b는 더 높은 지적 능력(61점) 을 바탕으로 S-Tier 품질(투명성)을 달성하면서도, 본 프로젝트의 핵심 비용인 ‘입력 비용’이 2.5배 더 저렴하다. 이 경쟁력은 지금과 같이 안정성 + 서비스의 목표 구현을 양 쪽으로 고려시 최선의 선택이 되리라 느꼈다.
1만 명 트래픽 시뮬레이션 결과, 총비용을 30% 이상 절감할 수 있고, ‘1만 명 트래픽’을 목표로 하는 DevOps 포트폴리오에서, 176 t/s는 ‘충분히 빠른’ 속도이며, 이 속도를 유지하면서 비용 절감까지 증명해낸 gpt-oss-120b가 가장 합리적이고 전략적인 선택이다. 또한 이 과정에서 가이드, 맥락 파악을 위한 프롬프트를 또 작성해 주는 것이 오히려 모델들의 잠재력을 끌어올릴 수 있다는 인사이트는 대단히 인상적이었다.
본 프로젝트의 성공은 ‘AI 모델’ 자체에 달린 것이 아니라, ‘꼼꼼한 프롬프트’ 로 ‘저렴하고 똑똑한 AI(gpt-oss-120b)’ 를 통제하는 개발자의 역량에 달려 있다는… 그런 내용이 아니었나 싶다.