 Paul's Archives
Paul's Archives

2025-10-31 ~ 2025-11-03 : Monitoring 서버 구축하기 & 네트워크 문제 해결하기
구축하고 있는 NextJS 와, MSA 백엔드 서비스, AI 에이전트를 위한 모니터링 시스템을 구축하고 이를 기반으로 지속적으로 서비스의 상태를 확인하며 프로젝트를 진행해 나가려고 한다.
서버 아키텍쳐 구조도

아키텍처 구성 요소 및 역할
1. 사용자 (Users)
- Admin (관리자): ‘모니터링 서버’의
Nginx_Mon을 통해 Grafana 대시보드에 접속하여 전체 서버 인프라의 상태를 확인한다. - Public User (일반 사용자): ‘메인 서비스 서버’의
Frontend애플리케이션에 접속하여 실제 모니터링 되고 있는 내용 중 일부를 볼 수 있다.
2. 모니터링 서버 (Ryzen 3400G)
- Nginx_Mon (HTTPS 프록시): Admin의 Grafana 접속 요청을 받아 HTTPS 암호화 통신을 처리하고, 내부의 Grafana 컨테이너로 요청을 전달(리버스 프록시)하는 게이트웨이이다.
- Grafana (데이터 시각화): Prometheus에 저장된 모든 지표(메트릭) 데이터를 가져와 관리자가 한눈에 볼 수 있도록 다양한 대시보드를 시각화한다.
- Prometheus (데이터 수집/저장): 모니터링의 핵심이다. 두 서버의 모든 Exporter로부터 주기적으로 지표를 수집(Scrape)하고 시계열 데이터베이스(TSDB)에 저장한다.
- NodeExporter_Mon (호스트 지표): 모니터링 서버 자체의 CPU, 메모리, 디스크, 네트워크 사용량 등 하드웨어 자원 지표를 Prometheus에 제공한다.
- cAdvisor_Mon (컨테이너 지표): 모니터링 서버에서 실행 중인 Docker 컨테이너(Prometheus, Grafana 등)들의 개별 리소스 사용량 지표를 Prometheus에 제공한다.
3. 메인 서비스 서버 (모니터링 대상)
- App_1 (Frontend): Public User에게 보여지는 웹 애플리케이션(Project Mini Frontend)이다.
- App_2 (Backend): 서비스의 비즈니스 로직을 처리하는 NestJS 및 FastAPI 기반의 MSA 백엔드 API 서버이다.
- NodeExporter_Svc (호스트 지표): 메인 서비스 서버 자체의 하드웨어 자원 지표(CPU, RAM 등)를 Prometheus에 제공한다.
- cAdvisor_Svc (컨테이너 지표): 메인 서비스 서버에서 실행 중인 모든 서비스 컨테이너(App_1, App_2 등)의 리소스 사용량 지표를 Prometheus에 제공한다.
프로세스
-
1단계: GitHub 리포지토리 구조 설계 및 초기화
- 단일 리포지토리 내에 모니터링 스택(Prometheus, Grafana)과 Exporter 스택(Node Exporter, cAdvisor)의 구성을 분리할 디렉터리 구조를 설계합니다.
- 예시 구조:
/monitoring-infra ├── monitoring-stack/ # [모니터링 서버(Ryzen 3400G)용] │ ├── docker-compose.yml │ └── prometheus/ │ └── prometheus.yml # Prometheus 설정 파일 └── service-exporters/ # [메인 서비스 서버용] └── docker-compose.yml
- 2단계: ‘service-exporters’ 구성 파일 작성
- 모니터링 대상 서버(메인 서비스 서버)에서 실행될
service-exporters/docker-compose.yml파일을 작성합니다. - 이 파일은 Node Exporter와 cAdvisor 컨테이너를 실행하는 내용을 포함합니다.
- 모니터링 대상 서버(메인 서비스 서버)에서 실행될
- 3단계: ‘monitoring-stack’ 구성 파일 작성
- 모니터링 서버(Ryzen 3400G)에서 실행될
monitoring-stack/docker-compose.yml파일을 작성합니다. - 이 파일은 Prometheus와 Grafana 컨테이너를 실행하는 내용을 포함합니다.
- 동시에
monitoring-stack/prometheus/prometheus.yml설정 파일을 작성합니다. 이 파일에는 2단계에서 실행될 Exporter들(메인 서비스 서버의 IP)을 수집 대상으로 지정합니다.
- 모니터링 서버(Ryzen 3400G)에서 실행될
- 4단계: 각 서버에 배포 실행
- [메인 서비스 서버에서]
- 프로젝트 리포지토리를
git pull합니다. service-exporters디렉터리로 이동합니다.docker-compose up -d를 실행하여 Exporter들을 활성화합니다.
- 프로젝트 리포지토리를
- [모니터링 서버(Ryzen 3400G)에서]
- 프로젝트 리포지토리를
git pull합니다. monitoring-stack디렉터리로 이동합니다.docker-compose up -d를 실행하여 Prometheus와 Grafana를 활성화합니다.
- 프로젝트 리포지토리를
- [메인 서비스 서버에서]
- 5단계: Grafana 대시보드 구성
- 웹 브라우저로 Grafana에 접속합니다.
- Prometheus를 데이터 소스로 추가합니다.
- Node Exporter 및 cAdvisor 용 대시보드를 Import하여 모니터링을 시작합니다.
문제 해결 및 개선 절차
1. 초기 스택 배포
- Docker Compose를 활용하여 모니터링 스택(Prometheus, Grafana) 및 Exporter(Node Exporter, cAdvisor) 컨테이너의 기본 배포를 성공적으로 완료하였다.
- Jenkins 서버 이전을 대비한 Nginx 리버스 프록시 기본 구성을 완료하였다.
2. 온프레미스 네트워크 다중화 구성
신규 모니터링 서버(Ryzen 3400G) 도입에 따라 발생한 네트워크 문제를 해결하는 과정이다.
2.1. 443 포트 점유 및 DDNS 라우팅 이슈
- 문제: 단일 공유기 환경에서는 443 포트(HTTPS)를 메인 서버와 모니터링 서버로 동시에 포트 포워딩할 수 없는 문제가 발생하였다.
- 분석: DDNS 서비스는 도메인을 공인 IP에 매핑할 뿐, 포트 레벨의 라우팅을 지원하지 않는다. 포트 분배는 라우터(NAT)의 역할이다.
- 1차 해결: 물리적 네트워크 분리를 위해 2번째 공유기와 USB 이더넷 어댑터를 도입하였다. 각 공유기에 별도의 공인 IP를 할당받아 443 포트 점유 문제를 해결하고자 시도하였다.
2.2. 게이트웨이 및 서브넷 충돌
- 문제: 두 공유기가 동일한 기본 서브넷(예:
192.168.0.x)을 사용함에 따라 게이트웨이 충돌이 발생하였고, 이로 인해 서브 공유기의 관리 페이지 접근이 불가한 현상이 나타났다. - 2차 해결: 서브 공유기의 LAN 및 DHCP 설정을
192.168.10.x와 같이 고유한 서브넷 대역으로 변경하여 네트워크를 논리적으로 분리하였다.
3. ISP 제약 및 아키텍처 변경
1, 2차 해결책이 ISP단의 제약으로 인해 새로운 문제에 직면하였다.
3.1. 공인 IP 다중 할당 제한
- 문제: ISP(KT) 모뎀에서 두 개의 공인 IP 할당 요청을 비정상적인 트래픽으로 간주, 특정 MAC 주소의 연결을 차단하는 문제가 발생하였다. 2.1에서 시도한 물리적 네트워크 분리(공유기 2대 사용)가 무효화되었다.
- 3차 해결 (아키텍처 변경):
- 클라우드 프록시 도입: 단일 진입점(Single Entry Point)으로 GCP 가상 인스턴스(VM)를 배치하였다.
- L4 프록시 전환: GCP의 Nginx를 L7(HTTP) 프록시가 아닌 L4(TCP) 프록시 모드로 설정하여 트래픽을 단순 전달(forwarding)하도록 하였다.
- SSL Passthrough 적용: 클라우드 프록시는 SSL/TLS 암호화를 복호화하지 않고, 암호화된 트래픽(TCP)을 그대로 온프레미스 서버로 전달한다.
- 종단간 암호화 유지: SSL Termination (암호화 복호화)은 최종 목적지인 온프레미스 Nginx 서버에서 직접 처리하도록 구성하여 종단간 암호화를 유지한다.
- Client IP 보존: Proxy Protocol을 활성화하여 L4 프록시 환경에서 유실될 수 있는 원본 클라이언트 IP를 백엔드 서버로 전달하였다.
- 결과: GCP 인스턴스를 경유하여 온프레미스 서버의 특정 포트(8888, 8889 등)로 트래픽을 성공적으로 포워딩하는 것을 확인하였다.
4. 현재 블로킹 이슈: 물리적 인프라 장애(국내 DHCP 환경의 특징 - 가정용만인듯?)
- 문제: ISP 모뎀 자체의 노후화 또는 물리적 결함으로 추정되는 인터넷 신호의 간헐적 끊김 현상이 발생하였다.
- 영향: 온프레미스 환경의 모든 서버(메인 서비스, 모니터링)가 외부에서 접근 불가능한 상태(unreachable)가 되었다.
- 현황: 모뎀 하드웨어 문제 해결 전까지 모든 서버 배포 및 설정 작업이 중단(Blocked)되었다. 현재는 문제 해결 과정을 문서화하며 대기 중이다. (후… KT)
- 분석 및 결론: 핵심 문제는 DHCP 관련된 문제였다고 발견되었다. 모뎀을 교체하여 신상으로 했는데도 동일 증상(붙었다 끊어졌다)가 반복 되었다. 거기다 주기적으로 붙었다 떨어지는것, 공유기는 이상이 없는 것을 발견하였다.
- 결국 설정을 뒤지다가 문제의 핵심이 ‘고정IP’ 라는 결론에 다다르게 된다.
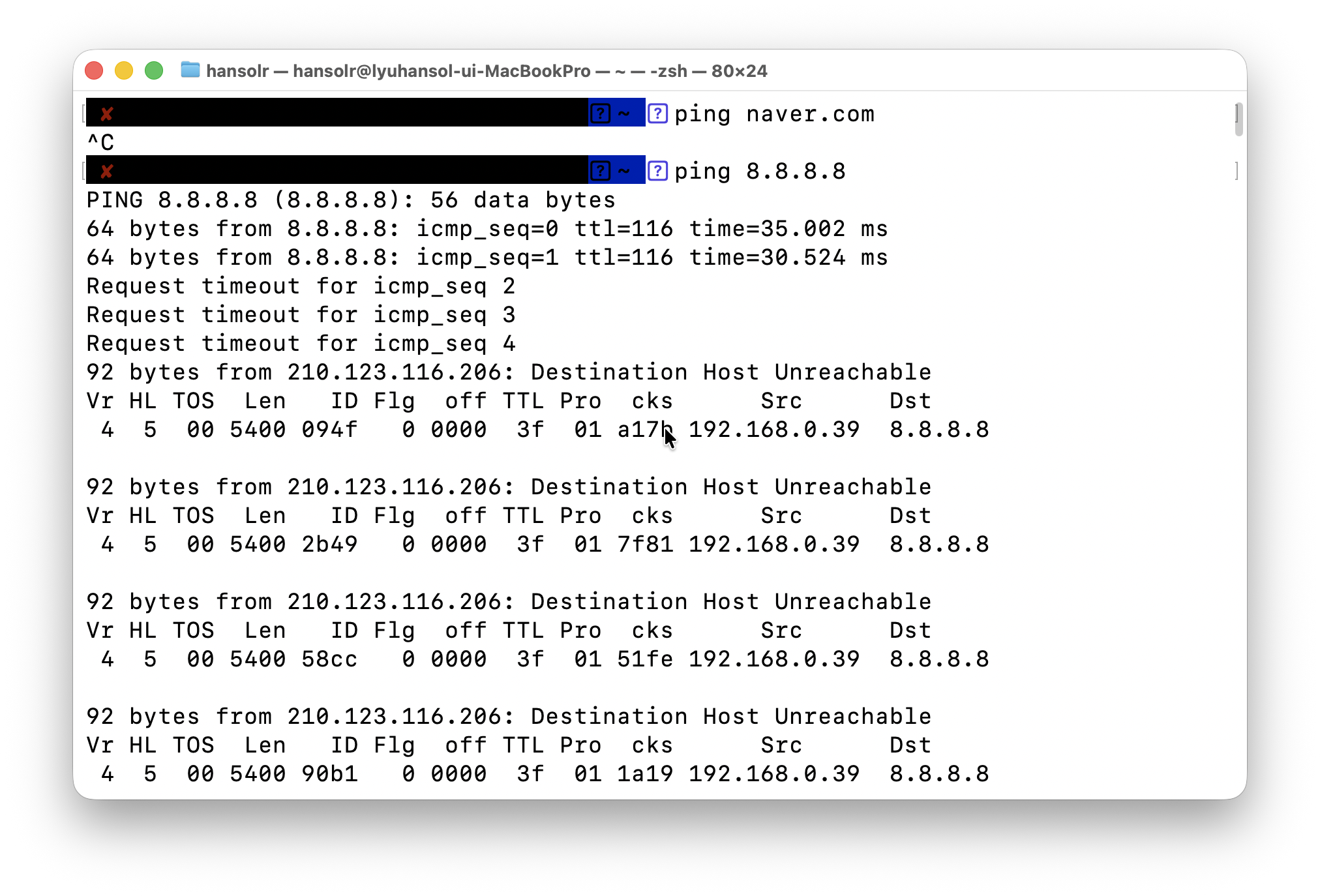

- 고정할당 문제: ISP 는 공인 IP 주소 풀을 독접 관리하고, 사용자에게 필요시 해당 IP 를 제공하는 방식을 사용한다. 그런데 여기서 기본적으로 임대를 해주는 개념이고 결과적으로 L2 레이어에서 요청-응답-승인-갱신 절차를 거친다. 문제는 거기서 내가 뭣도 모르고, 공유기를 ‘고정IP 방식’으로 했다. 내 의도는 내 공인 IP 를 그대로 유지해달라! 는 요청이었는데, 이건 제공하는 쪽과 수신하는 쪽, 사이에서 고정 할당을 해주고, 그 뒤에 고정 할당을 했을 때 문제가 없는 것이다..!
- DHCP 규약: 일방적으로 설정해두면, 공유기는 더이상 승인요청을 하지 않고, 갱신 요청을 보내지 않게 된다….ㅠㅠ 결과적으로 최초에 설정하거나, 연결이 끊어진 직후에 인터넷 시그널을 보내면 처음 성공한 상태에서 사용 가능한 시점까지만 제공 => 갱신없음 => 공유기에서 인터넷 패킷이 들어오지 않음 의 연속이었던 것이다(….)
- 고정 IP 로 변경이 DHCP 규약을 안따르겠다(갱신 안함)라는 의도를 포함한 설정이란 걸 몰랐기에 생긴 문제였다.
- KT 의 경우 ISP 에서 기본적으로 Sticky IP 정책을 쓰기 때문에 DHCP 프로토콜 규약은 지키지만, 어지간하면 IP 가 안바뀌고, 개인 프로젝트라면 문제가 없는 것으로 판단하고 유동IP 방식으로 변경하였다.
5. HTTPS 인증서 발급 Certbot과 Nginx 사이에 400 Bad Request 오류 발생
GCP(Google Cloud Platform) VM에 Nginx를 설치하여 프록시 서버로 구성했다. 목적은 443 포트(TLS)와 80 포트(HTTP)로 들어오는 트래픽을 내부망에 있는 ‘Centre 서버’로 전달(proxy pass)하는 것이다.
이후 HTTPS 인증서를 발급받기 위해 Centre 서버에서 Certbot을 실행했으나, 400 Bad Request 오류가 발생하며 인증이 계속 실패했다.
브라우저 개발자 도구로 확인 결과, 이 400 오류는 최종 목적인 Centre 서버가 아닌, 요청의 맨 앞단인 GCP 프록시 서버(35.197.5.162)가 직접 반환하는 것을 확인했다.
이번 문제의 핵심은 서로 다른 원인을 가진 두 개의 400 오류가 겹쳐 있었던 것이다.
1. GCP 서버: stream과 http 모듈 충돌 (핵심 원인)
-
원인: GCP 서버의 Nginx 설정(
nginx_target.conf)이 443 포트와 80 포트 모두를stream(TCP) 모듈로 처리하도록 되어 있었다. -
충돌: Certbot과 브라우저는 80 포트에
http(GET /...) 요청을 보냈다. Nginx의stream모듈은http문법을 이해하지 못하므로, 이를 ‘형식에 맞지 않는 요청’으로 간주하여400오류를 반환했다. -
해결: GCP 서버 Nginx 설정을 ‘하이브리드’ 모드로 수정했다. 443 포트는
stream블록(TCP 프록시)으로 유지하되, 80 포트는http블록으로 분리하여proxy_pass(HTTP 프록시)로 Centre 서버에 정상 전달되도록 조치했다.
2. Centre 서버: server_name 해시 버킷 제한
-
원인: Centre 서버의 Nginx 설정(
nginx_init.conf)은 4개의 긴 도메인 이름을 하나의server_name지시어에 모두 나열했다. 이는 Nginx의 기본server_names_hash_bucket_size(이름 처리 메모리) 제한을 초과하여400오류를 유발할 수 있는 잠재적 문제였다. -
해결:
http블록 자체의 메모리(server_names_hash_bucket_size 64;)를 늘리는 대신,server블록을 4개로 분리하여 각 블록이 1개의server_name만 처리하도록 구조를 변경함으로써 문제를 우회하고 해결했다.
현상황: DuckDNS 네임서버 응답 대기
GCP 서버와 Centre 서버의 Nginx 설정이 모두 완료되었다.
-
검증: 브라우저로 80 포트 접속 시, 의도했던 대로 GCP 프록시를 거쳐 Centre 서버의 Nginx가
404 Not Found를 정상적으로 반환한다. -
로그: Centre 서버의 Nginx 로그에도 Certbot의
.well-known경로 접근이200 OK로 성공 처리된 것이 확인되었다. -
현재 문제: Nginx 설정은 완벽하지만, Certbot은
DNS problem: SERVFAIL오류를 반환하며 여전히 실패한다. -
원인:
SERVFAIL은 로컬 Nginx 설정 문제가 아니다. Let’s Encrypt 인증 서버가 DuckDNS 네임서버에 DNS 조회를 시도했으나, DuckDNS 서버가 불안정하여 “서버 실패(Server Failure)” 응답을 반환한 것이다. -
상태: 모든 로컬 및 프록시 설정은 완료되었으며, DuckDNS 네임서버가 안정화되고 Let’s Encrypt의 ‘실패 캐시’가 만료되기를 대기 중이다.
6. Nginx, Jenkins, n8n 서버 구축
우선 안된 HTTPS 를 연결할 수 없으니 일단 HTTP 상태에서 세팅을 해보았다.
1. Nginx
- 설정 파일 수정 :
server { listen 80; server_name {도메인}; # Certbot 인증 경로 # 흑흑 얼른 되라고... location /.well-known/acme-challenge/ { root /var/www/certbot; } location / { # Docker 이미지의 기본 Host 가 정해진다. # n8n 의 경우 http://n8n-server:5678 이다 proxy_pass http://jenkins-server:8080; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; } } - 네트워크 공유:
- 도커 네트워크를 연결해야 한다. 하지만 개별 프로젝트로 관리되고 있는 상황에서 이걸 일일히 다시 하나의 Docker-compose 파일로 모으는 건 비효율적이라고 생각. 각자 사용하게 만들기 위해선 다음과 같이 하면된다.
docker network create {명칭}: 해당 명령어로 네트워크를 미리 사전에 설정해둔다.- 각각의 컴포즈 파일에
network항목에 해당 네트워크 명칭을 작성,networks항목에 해당 항목을 기재하고external: true라고 넣으면 된다.... 전략 networks: - my-central-proxy-network networks: my-central-proxy-network: external: true - 제대로 proxy 전달에 대해서만 가리키고 있다면, 이것으로 HTTP 접속은 구현된다.
2. Jenkins 서버 백업 및 복구
- 도커 네트워크를 연결해야 한다. 하지만 개별 프로젝트로 관리되고 있는 상황에서 이걸 일일히 다시 하나의 Docker-compose 파일로 모으는 건 비효율적이라고 생각. 각자 사용하게 만들기 위해선 다음과 같이 하면된다.
- 백업하기:
- 기본적으로 Jenkins 는 jenkins_home 이라는 폴더 내부 데이터를 통째로 옮기면 백업과 복원이 용이한 구조다. 이를 위해 볼륨도 호스트와 공유하도록 설정했다면, 손쉽게 통째로 백업 및 복원하면 된다.
tar -pczvf [압축파일명] [압축 대상 폴더]: p 가 중요한데, 단순히 진행하게 되면 소유권 문제가 발생할 수 있다(시스템의 유저명칭 등이 같더라도 UID, GID 등의 불일치 문제가 발생할 수 있으므로) 이때 해당 옵션을 추가시 해당 기록까지 그대로 가져가준다.
- 복원하기:
tar -xzvf [대상 압축파일명]: jenkins_home 동일하게 진행해주면 되고, 젠킨스 컨테이너를 재시작하면 완벽하게 복원된다.
- 문제상황: DooD 권한실패…!
- DooD 구조를 하다보니 GID 가 같지 않으면 안되는데, 이게 아무래도 확실히 다를 수 밖에 없었다. 기존 메인 서버의 임시 Jenkins 서버는 1001 번이었지만, 이번 서버는 998번(…)
- 자동으로 스크립트로 따오게 만들기도 가능하겠지만, 시간관계상 일단 하드코딩으로 Dockerfile에서 이를 설정해주는 작업을 해주었다.
ARG DOCKER_GID=984 RUN groupadd -g ${DOCKER_GID} docker RUN usermod -aG docker jenkins - DooD 랑 호스트의 도커 시스템을 마운트하여도커 컨테이너 내부에서 호스트를 이용해 빌드를 하는 방식이다. 이를 통해 호스트 자원을 그대로 가져다 쓰고, 제어만 커테이너가 하게 된다. 단, 권한 문제를 비롯 제어시 민감한 부분들을 설정을 잘 해줄 필요가 있다.
3. n8n 서버 HTTP 상에서 열어주기
- 환경변수 설정: HTTP 환경에선 쓰지 못하게 하는 것이 기본이다. 당연히 종단간 암호화가 안된 상태에서 이걸 진행하게 되면 누군가가 볼 가능성이 당연히 너무 크고, 따라서 중간 탈취를 막아야 하기 때문이다. 그러나 부득불 공개를 해야 한다 or 해도 된다면(내부망 사용 등) 환경 변수를 설정하면된다.
environment: - GENERIC_TIMEZONE=${GENERIC_TIMEZONE} - N8N_SECURE_COOKIE=false # 1. HTTPS가 아니어도 쿠키 사용 허용 - WEBHOOK_URL=${WEBHOOK_URL} # 2. n8n의 공개 주소 설정