 Paul's Archives
Paul's Archives
개요
현재 인공지능(AI) 기술 발전의 핵심에는 트랜스포머(Transformer) 아키텍처가 있으며, 2017년 구글의 ‘Attention Is All You Need’ 논문을 통해 소개된 이후 오늘날 가장 널리 사용되는 AI 모델 구조가 되었다. 챗GPT(ChatGPT)의 ‘GPT’는 ‘Generative Pre-trained Transformer’의 약자로, 방대한 데이터를 통해 사전 학습된 트랜스포머 모델임을 의미한다. 트랜스포머 모델은 텍스트 번역을 넘어 이미지 생성, 음성 변환 등 다양한 AI 분야에 활용되며, 다음 단어나 내용을 예측하는 방식으로 작동한다. 몇 개의 단어를 입력하면 모델이 다음 단어를 예측하고, 그 예측된 단어를 다시 입력으로 사용하여 반복적으로 긴 문장을 생성할 수 있다.
AI 기술의 발전 속도는 전례가 없는데, AI 사용자 및 사용량 증가는 인터넷보다 훨씬 빠르게 나타나고 있으며, 관련 자본 지출(CapEx) 또한 급증하고 있다. ChatGPT는 불과 5일 만에 100만 사용자를 확보하며 역사상 가장 빠른 사용자 채택을 기록했다.
오늘은 이러한 내용들을 정리해보면서, GPT에서 시작해 DeepSeek 까지의 발전 과정을 조금(?) 훑어 보려고 한다. 문돌이 입장에서 AI 의 힘을 여실히 빌려서 만든 내용이긴 하지만 AI 를 좀더 깊게 이해하고 싶은 모든이들에게 도움이 되길 기원한다.
LLM(Large Language Model)의 개요
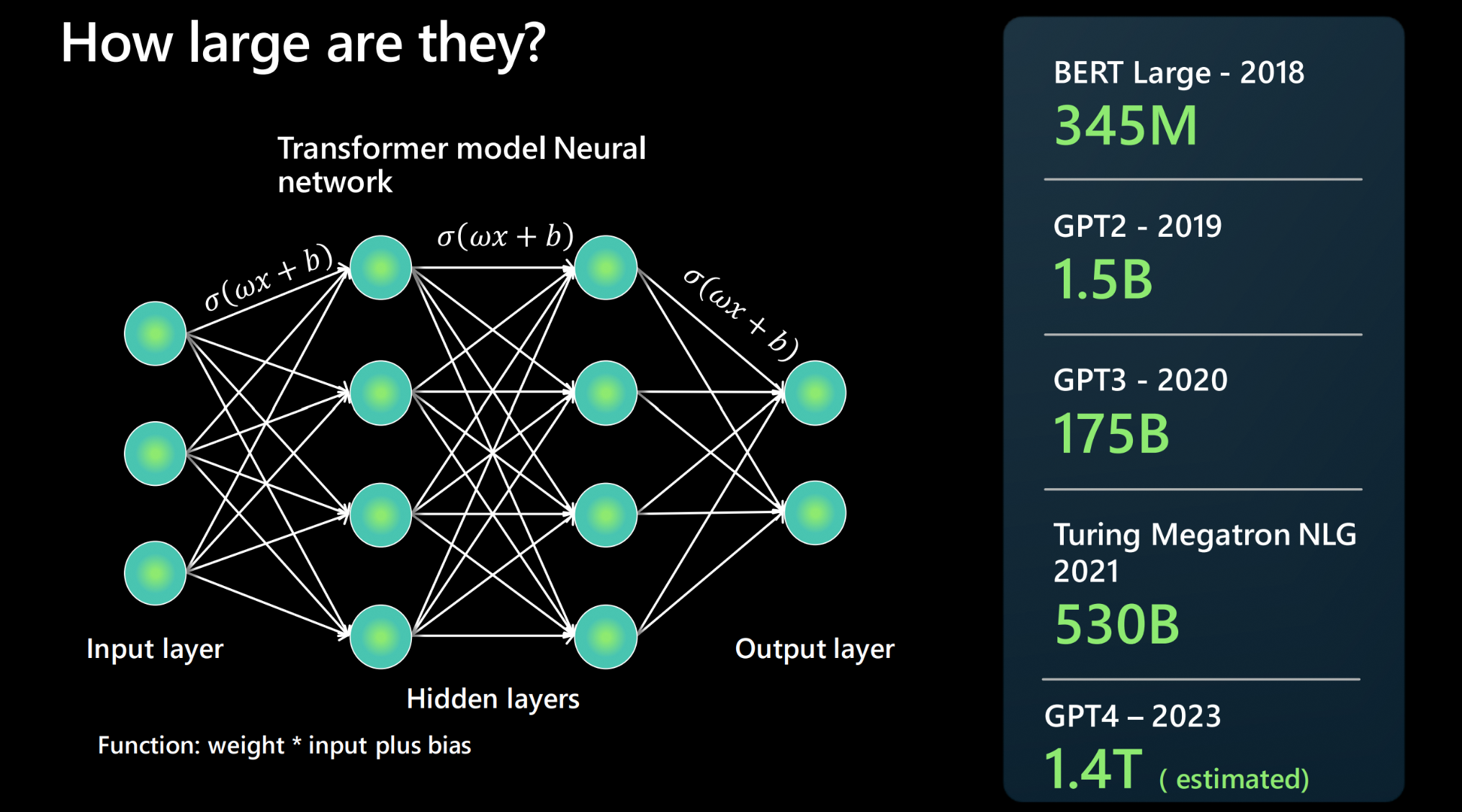
출처 : Microsoft AI Tour
대규모 언어 모델(Large Language Model, LLM)은 주어진 텍스트가 있을 때 다음에 올 단어를 예측하는 매우 정교한 수학적 함수이다. 더 정확하게는, 딱 하나의 단어를 확정적으로 예측하는 대신 다음에 올 단어들에 대한 확률을 계속해서 구하는 함수이다.
- 작동 방식: LLM은 몇 개의 단어를 입력으로 받아 다음 단어를 예측하고, 그 예측된 단어를 다시 입력으로 사용하여 반복적으로 긴 문장을 생성한다. 이는 챗GPT와 같은 모델과의 대화가 한 단어씩 생성되는 방식으로 이루어지는 이유이다.
- 학습 데이터: LLM은 인터넷에서 수집한 엄청난 양의 텍스트 데이터로 학습된다. 예를 들어, GPT-3가 학습한 텍스트 양은 사람이 24시간 쉬지 않고 읽었을 때 2,600년 이상이 걸릴 것이며, 요즘 모델들은 훨씬 더 많은 데이터로 훈련된다.
- 파라미터(매개변수) 및 훈련: 모델 속의 수많은 다이얼(파라미터 또는 가중치)을 조정해가며 학습이 이루어진다. LLM은 수백억 개에서 수천억 개까지 이르는 파라미터를 가지고 있으며, 처음엔 랜덤하게 설정된 이 값들이 훈련을 반복하며 점차 그럴듯한 예측을 할 수 있도록 조정된다.
- 역전파(Backpropagation): 훈련 시 마지막 단어를 제외한 나머지를 모델 입력으로 넣고, 모델이 마지막 단어를 어떻게 예측하는지 확인한 후, 그 예측이 정답에 가까워지도록 파라미터를 조정하는 알고리즘이다.
- 강화 학습(RLHF): 사전 훈련된 모델은 사람이 모델의 잘못된 응답을 직접 수정하거나 더 나은 응답을 골라주는 RLHF(Reinforcement Learning from Human Feedback)와 같은 강화 학습을 통해 추가 학습된다.
LLM의 속성을 이해하자
LLM vs NLP
기존 자연어 처리의 기술과 LLM 이 다른 점은 다음과 같이 설명할 수 있다.
- 기존 NLP 는 기능 당 하나의 모델이 필요하다.
- 기존 NLP 는 한정된 레이블 데이터 셋에서 학습을 시킨다. (예시, 특정 물체 인식 AI 를 위해 특정 물체의 사진을 수십만장 준비한다.)
- 기존 NLP 는 특정 사용 사례에 고도로 최적화 된다.(예시, 특정 물체의 데이터셋으로 학습된 특화 모델)
그러나 LLM은
- 여러 NLP 사용 사례에 단일 모델 사용이 가능하다(범용적이다).
- 수 TB 에 달하는 레이블이 없는 데이터에서 학습된 모델이다(기초).
- 개방형 사용 - 자연어를 사용하여 모델에 무언가를 ‘프롬프트’ 하도록 한다. 즉 자연스럽게 다양한 질문을 할 수 있고, 모델이 이에 맞춰 콘텐츠를 생성해 낸다.
LLM 이 하지 못하는 것은?
대규모 언어 모델은 강력한 생성형 AI 경험을 제공하고, 이 콘텐츠의 범용성은 지금의 AI 상황의 판도 자체를 뒤집어 엎는 일을 만들어 냈지만, 그 표현, 행위가 다음은 아니라는 사실을 명확히 해야 한다.
- 언어를 이해한게 아니다 : LLM은 예측 엔진, 예측 함수셋에 가깝기에 이것이 해당 콘텐츠의 문맥이나 의미를 이해한 거라고 말할 수 없다.
- 사실을 이해하지 못한다 :
정보 검색,창의적 글쓰기를 위한 별도의 모드가 있는 건 아니고, 진행중인 시퀀스에서 다음으로 가능성이 높은 토큰을 예측하는 것이기에, 그것이 ‘사실’이냐 ‘주장’이냐와 같은 해석은 LLM 자체에서는 무의미하다. - 매너, 감정, 또는 윤리를 이해하지 못한다 : 인간이 설계하고 설정한 데이터, 프롬프트에 의해 최적의 예측값을 ‘보정한’ 결과이지, 모델이 매너나 감정, 윤리를 이해하고 동작하는 것이 아니다. 결과적으로 LLM 은 통계적 패턴의 예측의 연속이며, 인간처럼 문장의 의미, 맥락을 이해하는 것이 아니다.
트랜스포머의 핵심 개념
트랜스포머는 텍스트를 처음부터 끝까지 순차적으로 읽는 대신, 전체 문장을 한꺼번에 병렬로 처리한다. 이 과정에서 문장 내 각 단어는 AI가 이해할 수 있는 숫자 벡터로 변환되어 서로의 관계성을 알 수 있게 된다.
- 토큰(Token):
- 트랜스포머는 입력된 문장이나 데이터를 토큰이라는 작은 조각으로 나누어 처리한다.
- 텍스트의 경우, 단어나 단어의 일부, 또는 일반적인 문자 조합이 토큰이 될 수 있다.
- 이미지나 음성이 포함될 때는 그 이미지의 작은 조각이나 음성의 작은 부분이 토큰이 될 수 있다.
- 벡터(Vector) 및 단어 임베딩(Word Embedding):
- 각 토큰은 해당 부분의 의미를 담도록 설계된 숫자 목록인 벡터와 연결된다. 이 벡터들은 고차원 공간의 좌표로 생각할 수 있으며, 의미가 비슷한 단어들은 그 공간에서 가까운 벡터로 배치되는 경향이 있다.
- 예를 들어, GPT-2에서는 768차원, DeepSeek R1에서는 7,168차원의 벡터가 단어 하나를 표현하는 데 사용된다.
- 훈련 과정에서, 모델은 학습을 통해 공간 속의 방향들이 어느 정도 의미를 가지도록 벡터를 정리한다. 예를 들어, ‘여자’와 ‘남자’ 사이의 벡터 차이가 ‘왕’과 ‘여왕’ 사이의 차이와 유사하게 나타날 수 있다. 이러한 차이 벡터 사이의 차이는 단어들 사이의 관련성이나, 어떤 특성을 나타낼 수 있다. 성의 차이, 복수와 단수의 차이 등 이러한 특성을 수학적 - 수치적으로 이해한 것이다.
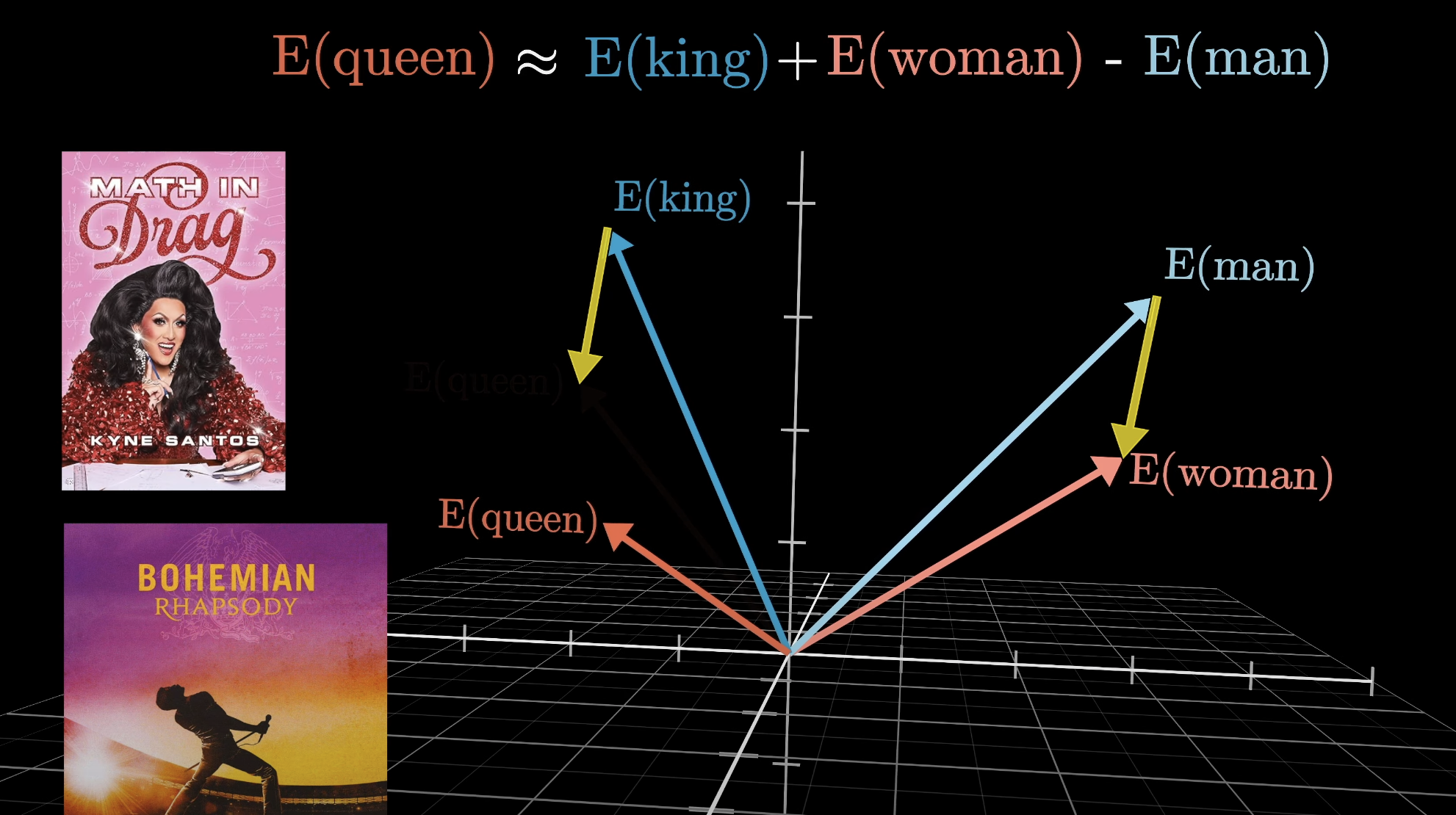
단어 사이의 관계성이 벡터 사이의 간격으로 이해가 될 수 있다. 출처 : 3Blue1Brown 한국어
- 어텐션(Attention):
- 트랜스포머의 핵심 연산으로, 입력된 벡터들이 ‘어텐션 블록’을 통과하며 서로 정보를 주고받고 값을 업데이트하는 과정이다. 이는 문맥을 파악하기 위해 단어들 간의 유사성을 계산하는 방식이다.
- 쿼리(Query), 키(Key), 밸류(Value): 어텐션은 ‘쿼리(Query)’, ‘키(Key)’, ‘밸류(Value)’라는 세 가지 개념을 통해 구현된다. 입력된 단어들(벡터 X)은 각각 고유한 학습 가능한 가중치 행렬(WQ, WK, WV)과 곱해져 쿼리 행렬, 키 행렬, 밸류 행렬로 변환된다. 단 이 개념이 별개의 정보라기 보단 결국 벡터 X 에서 나온다는 점은 명확하게 인지해야 한다.
- 쿼리(Query)는 하나의 ‘질문’ 역할을 한다.
- 키(Key)는 그 질문을 해결할 가능성이 있는 ‘열쇠’ 중 하나이다.
- 밸류(Value)는 어텐션 패턴에 따라 이동되거나 결합될 실제 정보의 ‘재료’이다.
- 내적(Dot Product): 쿼리가 키들과의 유사도를 계산하는 과정은 수학적으로 두 벡터의 내적으로 구현된다. 내적은 기하학적으로 벡터들이 비슷한 방향일 때 양수, 직교할 때 0, 반대 방향일 때 음수가 된다.
- 어텐션 패턴(Attention Pattern): 모든 쿼리와 키의 유사도를 계산하여 얻는 종합된 정보이다. 이 어텐션 패턴의 크기는 입력 단어 수의 제곱에 비례하여 늘어난다. 훈련 과정에서는 다음에 올 단어를 ‘컨닝’하지 못하도록 어텐션 패턴의 오른쪽 윗부분이 가려진다.
- 소프트맥스(Softmax): 유사도 계산 후, 각 행의 합이 0이 되도록
정규화하는 함수이다. 이 함수는 어떠한 숫자들의 나열이든 0과 1 사이의 값으로 변환하여 합이 1이 되는확률 분포로 만들어준다. 가장 큰 값은 1에 가깝고 작은 값은 0에 가까워진다. 또한온도(Temperature)라는 상수를 사용해 예측의 다양성을 조절할 수 있다. (이 온도는 열역학의 개념과 유사한 동작이기에, 그대로 차용했다.) - 어텐션 헤드(Attention Head): 어텐션 패턴 하나를 계산하는 단위를 ‘어텐션 헤드’라고 부른다. 여러 헤드가 각기 다른 쿼리, 키, 밸류 세트를 사용하여 독립적으로 패턴을 계산한 뒤, 이 값들을 종합하여 다음 레이어의 입력으로 사용한다.
- 피드포워드 네트워크(Feedforward Network): 트랜스포머 안에 포함된 또 다른 연산으로, 모델이 더 많은 언어 패턴을 저장할 수 있도록 돕는다.
트랜스포머의 연산량 문제와 기존 해결책
트랜스포머는 위에서 언급한 어텐션 헤드의 단위로 토큰이 아웃풋이 되고, 그것을 다시 인풋으로 집어넣는 것의 연속이다. 따라서 행렬의 엄청난 연산량을 요구한다는 문제가 있다. 어텐션 패턴의 크기가 입력 단어 수의 제곱에 비례하여 늘어나기 때문에, 몇 문장에서 시작해 책 한권 분량이 들어간다면 기하급수적이라는 것이 무엇인가를 알 수 있게 된다. 이러한 본질적인 구조로 CPU 연산이 아닌 GPU의 사용이 핵심일 수 밖에 없고, 동시에 GPU 의 사용이라 함은 막대한 전기 사용, 발열 등 ‘GPU가 녹는다’ 라는 말에 딱 부합하는 작업인 것이다. (물론 최신 AI 모델들, 특히 구글에선 TPU 를 활용하는 시도라던지, 다양한 시도가 있는 것은 사실이다.)

GPUs Are Melting: … 출처 : SNEHASISH DUTTA
이러한 비효율성을 줄이기 위해 개발된 핵심 기술이 키-밸류(Key-Value) 캐싱(KV Caching)이다.
- 키-밸류 캐싱(KV Caching): 이미 모델에 입력된 단어들의 쿼리, 키, 밸류 값은 다시 계산할 필요 없이 저장해두고 재활용하는 방식이다. 이 기술을 사용하면 어텐션 연산량이 단어 수에 선형적으로만 증가하도록 안정화되어 폭발적인 증가를 막는다.
- 저장 공간 문제: 그러나 KV 캐싱은 키-밸류 값을 저장하기 위한 막대한 저장 공간을 요구한다. 단어 하나당 키-밸류를 모두 저장하면 4MB를 차지하며, 10만 개의 단어를 처리할 경우 무려 400GB에 달하는 저장 공간이 필요할 수 있다.
위의 내용에서 언급한 저장공간 문제에 대해 이해하기 위하여, 간략화된 캐시 항목의 수를 계산 식은 다음과 같이 표현된다.
$CacheCounter = 2 \cdot n \cdot d_h \cdot n_h \cdot l$
- $n$ : 입력 토큰 수
- $d_h$ : 키/ 값 행렬의 차원
- $n_h$ : 레이어 당 어텐션 헤드 수
- $l$ : 레이어 수
예를 들어
$let d_h = 128, n_h = 128, l = 61, n = 100000$ (DeepSeek R1/V3 아키텍쳐 기준)
$(2)(128)(128)(61)(2) = 3.998 * 10^6 Bytes/token = (approx)4MB/token$
$4MB/Token * 100000 tokens = 400GB$
이러한 저장 공간 문제를 해결하기 위한 이전 시도에는 두 가지 방식이 있었다:
- 멀티-쿼리 어텐션(Multi-Query Attention): 모든 어텐션 헤드가 동일한 키-밸류를 공유하는 전략이다. 이는 저장 용량을 크게 줄일 수 있지만, 각 헤드의 역할이 달라야 하는 점을 방해하여 모델 성능이 저하된다는 단점이 있다.
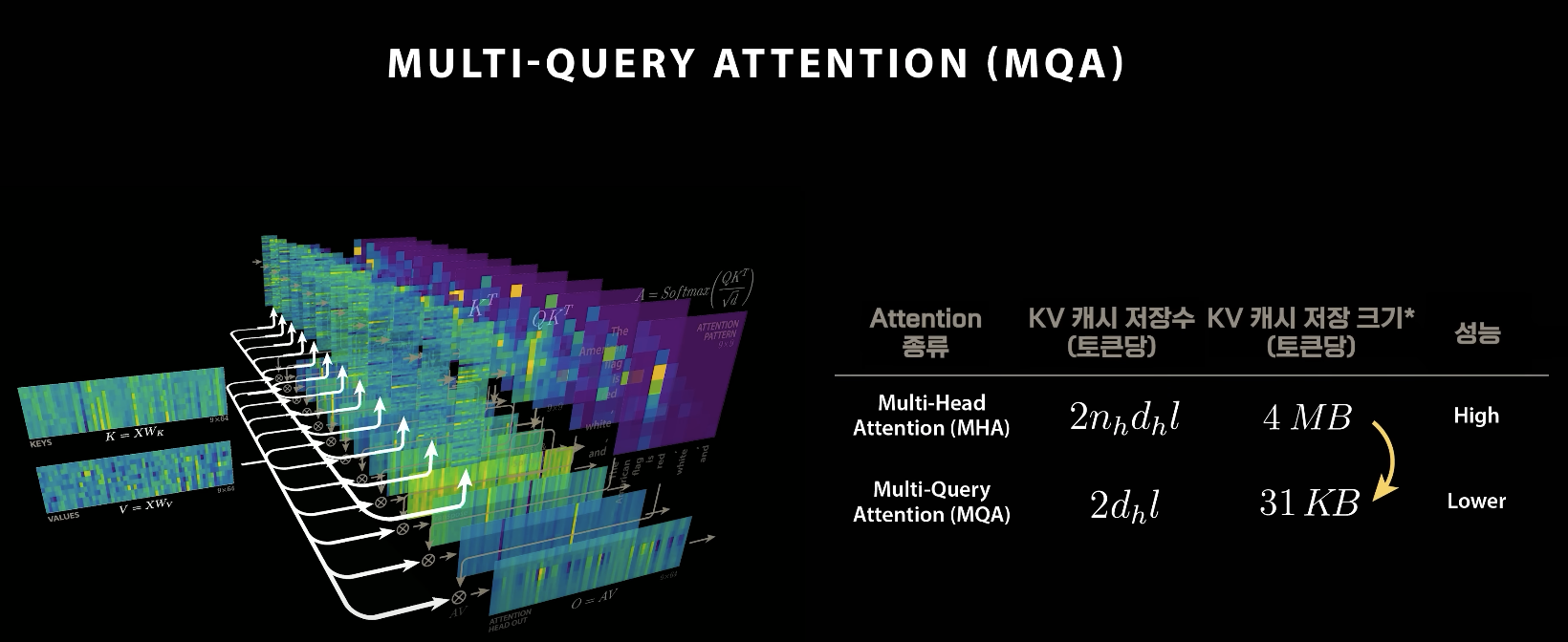
출처 : 웰트랩스
- 그룹별 쿼리 어텐션(Grouped-Query Attention): 멀티-쿼리 어텐션을 개선하여 어텐션 헤드를 여러 그룹으로 묶어
같은 그룹끼리 키-밸류를 공유하는 방식이다. 메타의 라마 3(Llama 3) 모델이 이 방식을 사용하여 저장 공간을 8배 절약했지만, 여전히 전체 헤드가 키-밸류를 저장하는 방식보다 성능이 못 미쳤다.
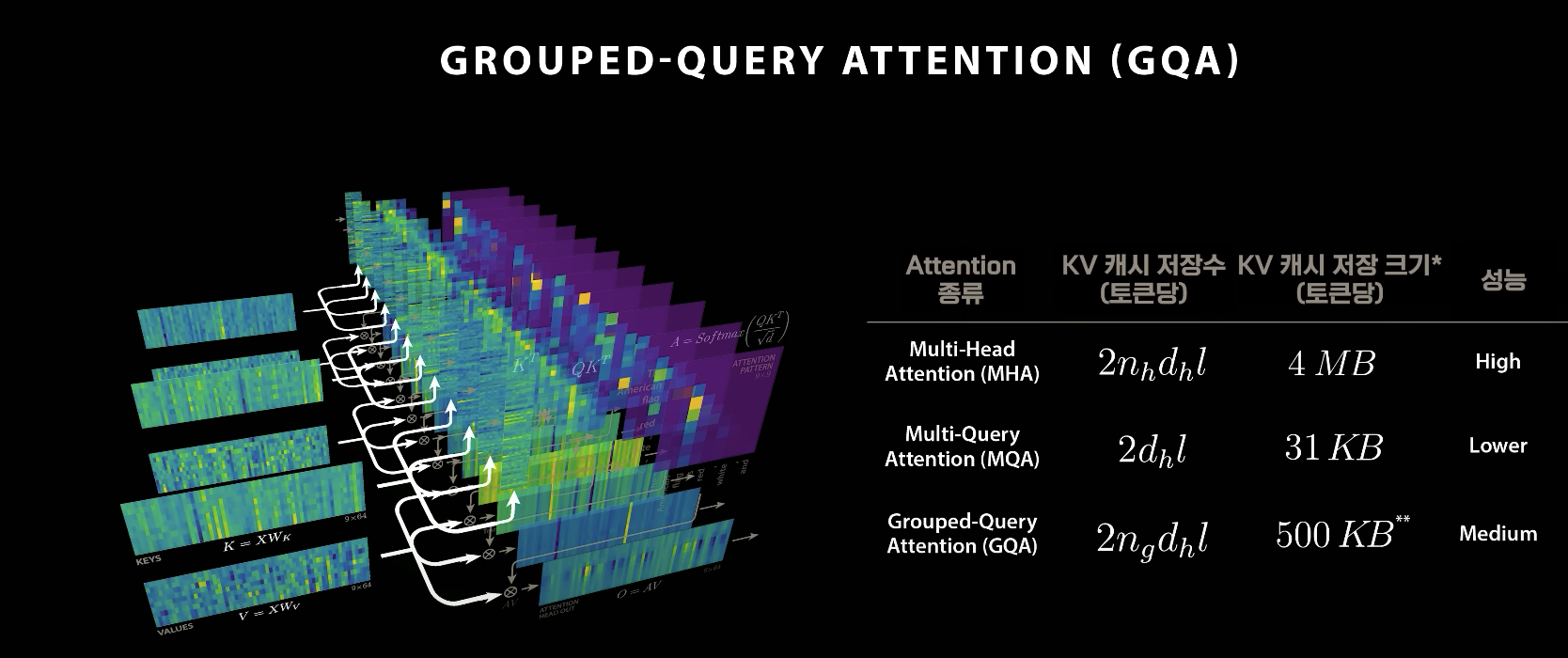
출처 : 웰트랩스
DeepSeek의 혁신: Multi-Head Latent Attention
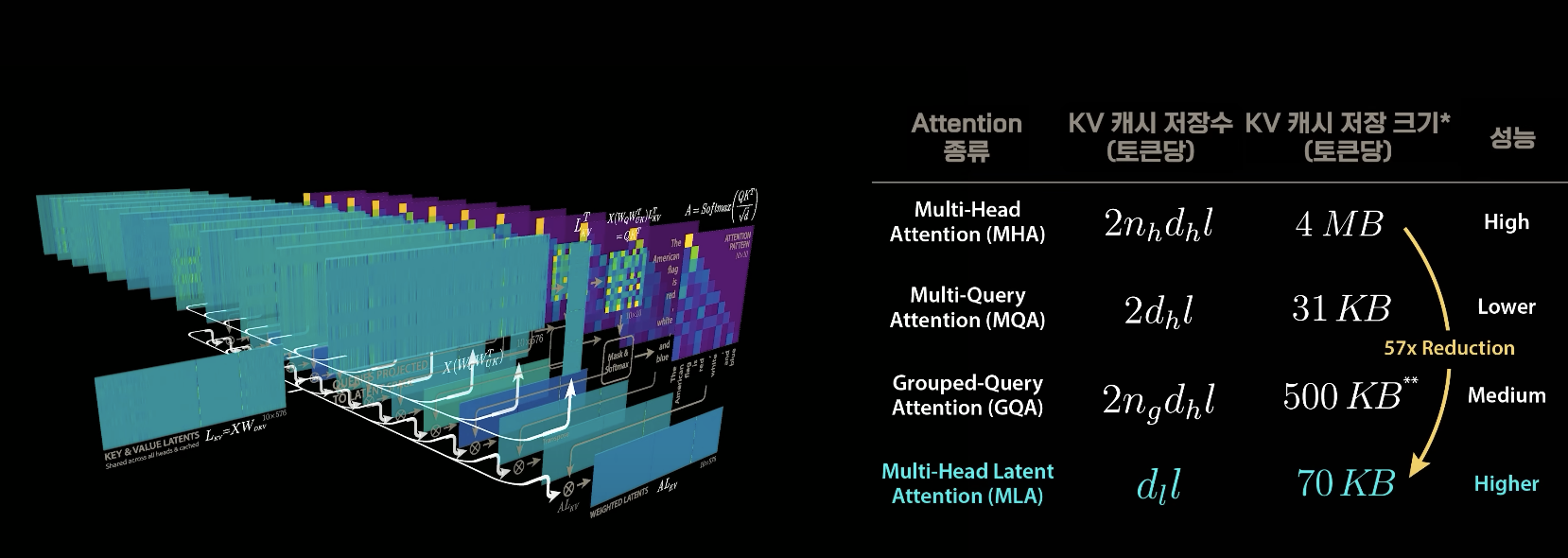
출처 : 웰트랩스
이러한 상황에서 중국의 딥시크(DeepSeek)는 기존 AI 개발에 수천억 원이 들어가는 것을 고작 80억 원에 가능하다고 발표하며 세상을 놀라게 했다. 딥시크는 경쟁사의 모델을 모방했다거나 실제 개발 비용보다 축소 발표했다는 구설수가 있었으나, 모든 모델 웨이트와 코드, 그리고 12개에 달하는 디테일한 논문까지 모두 공개하며 그 기술력을 드러냈다.
딥시크의 핵심 기술은 저장 공간과 연산량이라는 두 마리 토끼를 모두 잡은 멀티-헤드 레이턴트 어텐션(Multi-Head Latent Attention)이다. 이 기술은 인공지능 압축과 효율의 핵심인 ‘잠재 공간(latent space)’ 개념을 적용했다.
- 멀티-헤드 레이턴트 어텐션의 원리: 기존 멀티-헤드 어텐션에서 입력 X를 키-밸류로 만드는 중간에 압축하는 스테이지를 하나 추가한다. 모든 어텐션 헤드는 같은 잠재 공간을 공유하는데, 이는 멀티-쿼리 어텐션과 유사하게 저장 공간을 줄이는 데 효과적이다. 그러나 구체적인 값을 저장하는 대신, 각 헤드에서 압축된 잠재 공간으로 보내줄 가중치(Wv와 W)를 학습하는 문제로 바꾸어
학습 과정에서 실제 단일한 캐싱 전략으로 가서 용량을 줄이는 경우 보다더 많은 자유도를 보장한다. - 수학적 효율성: 기본적인 선형 대수의 원리를 활용하여, 훈련 시 합쳐진 모델 자체로 훈련하기 때문에 추론(inference) 상황에서 추가적인 연산이 필요 없다. 새로운 단어가 입력될 때도 쿼리 레이턴트를 만들고 저장해 둔 레이턴트 키-밸류를 사용하므로 효율적이다.
- 성능 개선: 이 덕분에 딥시크 R1은 키-밸류 캐시를 저장할 때 어텐션 헤드 개수가 아니라 공유된 키-밸류 캐시의 크기에만 영향을 받도록 설계되었다. 이는 토큰당 70KB만 사용하여 저장 공간을 57배나 줄였으며, 토큰 생성 속도를 6배 빠르게 만들었다. (참고로, 키-밸류 캐시를 모두 저장했다면 토큰당 4MB, 그룹별 쿼리 어텐션은 500KB를 필요로 했을 것이다). 이러한 트랜스포머의 알고리즘 개선은 기존보다 훨씬 빠른 토큰 생성을 가능케 한다는 점에서 주목할 만하다.
LLM의 잠재력과 그 가치
LLM 의 구조를 씹어먹어보고, 수학적 기초는 처음에는 대단히 어렵게 와닿았지만, 결국 단어들 사이의 예측, 입력이 다시 출력이 되고, 그 출력이 다시 입력이 된다는 이 구조에 대한 이해가 있게 되면 Transformer 와 LLM 의 아주 베이직한 표면의 이해에는 어렵지 않다.
하지만 거기에 더 많은 구조적, 효율적 개선, 그리고 LLM 의 보편성을 이용한 다양한 능력, 다시 특화 기능을 위한 모델로 학습하거나 아예 대형 모델을 기반으로 더 튜닝하는 SLM(Small Language Model)의 등장 등, LLM의 잠재력, 그리고 향후에도 지속적인 판도는 이어질 것이다.
이번 내용을 통해 좀더 LLM 을 실증적으로 이해하고, 특히나 DeepSeek 와 같은 개선의 여지가 여전히 있단 점들은, 앞으로 정말 AI를 거쳐 AGI 까지, 초 거대모델들의 성장 폭은 남아 있다는 점을 나름 생각해 볼 수 있는것 같다.