 Paul's Archives
Paul's Archives
2025-11-05 : Monitoring 서버 구축하기
드디어 모든 문제를 해결하였다. HTTPS 를 통한 종단암호화를 마쳤으며 네트워크를 선행 구축하여 통로로 연결될 수 있도록 설정하였다. 이제 남은 단 하나… 모니터링…!!
서버 아키텍쳐 구조도

핵심 설정 과정 및 트러블슈팅 (Q&A)
구축 과정에서 몇 가지 중요한 개념과 문제를 마주했으며, 이를 해결하는 과정이 이번 TIL의 핵심이다.
핵심 네트워크구조
네트워크의 설정이 난해했지만, 결국 핵심은 ‘외부’와 ‘내부’에 대한 명료함이다.
- 내부 통신 (Docker Network): 모니터링 서버 내부 의 컨테이너들(e.g.,
centre-prometheus,centre-grafana,NPM)은 docker의 가상 네트워크를 통해 컨테이너 이름으로 통신한다. 이 통신은 Docker가 내부 DNS를 통해 처리하므로 외부 포트가 필요 없다.- 예시: NPM 프록시 설정 시 Grafana의 주소는
http://centre-grafana:3000이 된다.
- 예시: NPM 프록시 설정 시 Grafana의 주소는
- 외부 통신 (Physical LAN): 모니터링 서버가 다른 물리적 서버에 접근할 때는 이 가상 네트워크를 쓸 수 없다. 반드시 외부 서버의 물리적 IP 주소와
service-exporters에서ports로 외부에 노출시킨 포트(9100,8081)를 사용해야 한다.
restart 정책으로 always 대신 unless-stopped를 써야 한다
사실 항상 restart 의 정책이 어떻게 되는지 정확하게 알고 있지 못했기에 이번 기회에 알아보았다. 두 정책 모두 시스템 재부팅 시 컨테이너를 자동 재시작해준다. 하지만 결정적인 차이가 있다.
restart: always: 관리자가 유지보수를 위해docker stop명령으로 컨테이너를 수동 정지 해도, Docker 데몬이 재시작되거나 시스템이 재부팅되면 컨테이너를 다시 켜버린다.restart: unless-stopped: 관리자의 수동 정지 명령을 “존중”한다. 즉, 수동으로 정지된 컨테이너는 관리자가 명시적으로 다시 시작(docker start)하기 전까지는 꺼진 상태를 유지한다.
이러한 결정적인 차이 때문에 유지보수 및 예측 가능성 측면에서 unless-stopped가 훨씬 안전한 정책이기에 향후엔 unless-stopped를 쓰려고 한다.
prometheus_data, grafana_data를 .gitignore에 추가해야 하는가?
설정을 찾아보다 보니, 볼륨의 연결이 필요했다. 이에 진행하면서, 해당 볼륨의 특성을 보았다. 처음엔 생성되는 것들이 git 으로 버전 관리되는걸로 하면 권한 문제가 생길 수 있다고 판단했었다. 하지만… docker-compose.yml에서 Named Volume (grafana_data:/var/lib/grafana)을 사용하기에 그럴 필요가 없다는 것을 배웠다.
- Named Volume: Docker가 관리하는 별도의 시스템 경로(
/var/lib/docker/volumes/...)에 데이터를 저장한다. Git 리포지토리 폴더 내에 파일이 생성되지 않으므로.gitignore가 필요 없다. - Bind Mount: 만약 프로젝트 폴더에 직접 데이터를 저장하는 방식 (
./grafana_data:/var/lib/grafana)을 사용했다면, 이 폴더는 Git이 추적하게 되므로.gitignore에 반드시 추가해야 했을 것이다.
Prometheus와 Grafana의 CPU/메모리 제한은?
제한된 온프레미스 서버. 최적화된 설정을 위해 Docker 의 리소스 관리 기능을 활용하려고 생각하고, AI 와 이야기하며 현실적인 수준을 파악해보았다. 현재 설정된 리소스(Prometheus 0.5 CPU/512M, Grafana 0.3 CPU/256M)는 2대의 서버(호스트 2개 + 컨테이너 수십 개)를 모니터링하기에 충분히 넉넉하다는 판단 하에 설정하였다.
다만, 처음엔 이정도가 맞는가? 라는 의문은 가지고 있었다. 아무리 생각해도 이정도는 하고, 윈도우 95 시절인줄 알았지만…. AI가 제시한 의도를 보고 파악할 수 있었다. 이 리소스 제한의 주 목적은 성능 자체가 아니라, 만약의 버그나 매우 복잡한 쿼리로 인해 모니터링 컨테이너 하나가 서버의 전체 리소스를 고갈시켜, 모니터링 시스템은 물론 서버 전체를 다운시키는 것을 방지하는 ‘안전벽(safety wall)’ 역할을 하고, 그렇게 볼때 다소의 보수적인 설정은 충분히 설득력이 있었다.
최종 설정 파일
위의 모든 과정을 거쳐 완성된 최종 설정 파일들이다.
1. 메인 서비스 서버 (A5 Server)
service-exporters/docker-compose.yml:
# main server watcher for monitoring structure
services:
#########################################################
# NodeExporter_Svc: 호스트 지표 (CPU, RAM, Disk)
#########################################################
node-exporter:
image: prom/node-exporter:latest
container_name: a5-node-exporter
restart: unless-stopped
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
pid: host
deploy:
resources:
limits:
cpus: '0.1'
memory: '64M'
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
#########################################################
# cAdvisor_Svc: 컨테이너 지표 (Docker)
#########################################################
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: a5-cadvisor
restart: unless-stopped
ports:
- "8081:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
devices:
- /dev/kmsg
deploy:
resources:
limits:
cpus: '0.15'
memory: '128M'
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
2. 모니터링 서버 (Centre Server)
monitoring-stack/docker-compose.yml:
# monitoring structure + sub server watcher
services:
#########################################################
# Prometheus: The core data collection service
#########################################################
prometheus:
image: prom/prometheus:latest
container_name: centre-prometheus
restart: unless-stopped
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
networks:
- my-central-proxy-network
deploy:
resources:
limits:
cpus: '0.5'
memory: '512M'
#########################################################
# Grafana: The data visualization dashboard
#########################################################
grafana:
image: grafana/grafana:latest
container_name: centre-grafana
restart: unless-stopped
volumes:
- grafana_data:/var/lib/grafana
networks:
- my-central-proxy-network
deploy:
resources:
limits:
cpus: '0.3'
memory: '256M'
#########################################################
# NodeExporter_Mon: Host metrics for THIS server
#########################################################
node-exporter-mon:
image: prom/node-exporter:latest
container_name: centre-node-exporter
restart: unless-stopped
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
pid: host
networks:
- my-central-proxy-network
deploy:
resources:
limits:
cpus: '0.1'
memory: '64M'
#########################################################
# cAdvisor_Mon: Container metrics for THIS server
#########################################################
cadvisor-mon:
image: gcr.io/cadvisor/cadvisor:latest
container_name: centre-cadvisor
restart: unless-stopped
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
devices:
- /dev/kmsg
networks:
- my-central-proxy-network
deploy:
resources:
limits:
cpus: '0.15'
memory: '128M'
#########################################################
# Shared Volumes and Networks
#########################################################
volumes:
prometheus_data:
grafana_data:
networks:
my-central-proxy-network:
external: true
name: my-central-proxy-network
3. 모니터링 “두뇌” (Prometheus Config)
monitoring-stack/prometheus/prometheus.yml:
global:
scrape_interval: 15s # How often to scrape targets
scrape_configs:
# 1. Monitor Prometheus itself (Internal)
- job_name: 'prometheus'
static_configs:
- targets: ['centre-prometheus:9090']
# 2. Monitor the monitoring server's HOST (Internal)
- job_name: 'monitoring_host'
static_configs:
- targets: ['centre-node-exporter:9100']
# 3. Monitor the monitoring server's CONTAINERS (Internal)
- job_name: 'monitoring_containers'
static_configs:
# cAdvisor's default port inside the container is 8080
- targets: ['centre-cadvisor:8080']
# 4. Monitor the REMOTE main service server's HOST (External)
- job_name: 'service_host'
static_configs:
# A5 Server's physical IP and exposed port
- targets: ['192.168.0.37:9100']
# 5. Monitor the REMOTE main service server's CONTAINERS (External)
- job_name: 'service_containers'
static_configs:
# A5 Server's physical IP and exposed port
- targets: ['192.168.0.37:8081']
4. .gitignore
.DS_Store
Thumbs.db
.env
*.env.local
docker-compose.override.yml
결과
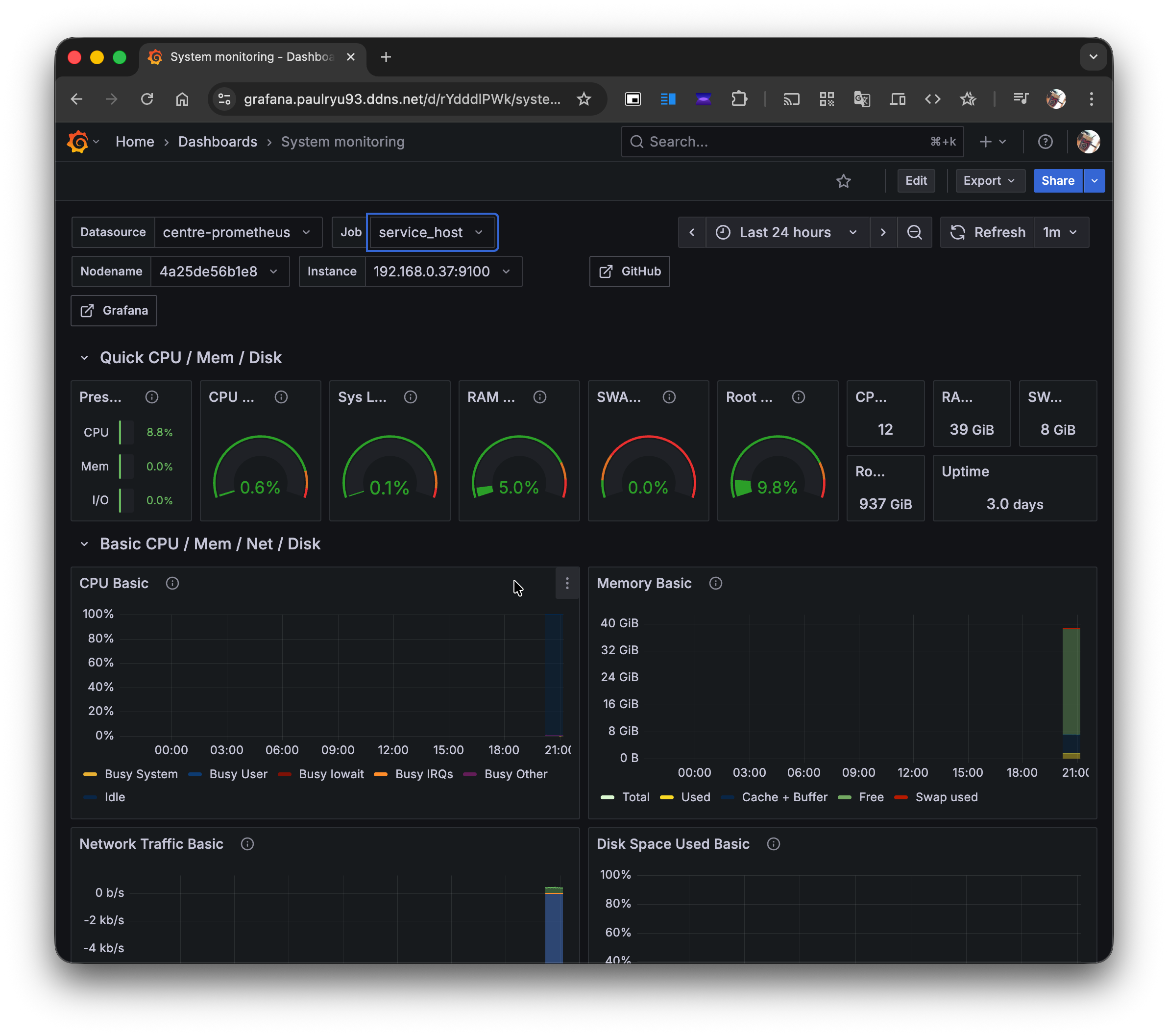
모든 설정이 완료되고, Grafana에서 https://grafana.paulryu93.ddns.net에서 모든걸 볼 수 있었다.

Node Exporter (monitoring_host) 대시보드:

cAdvisor (monitoring_containers) 대시보드:
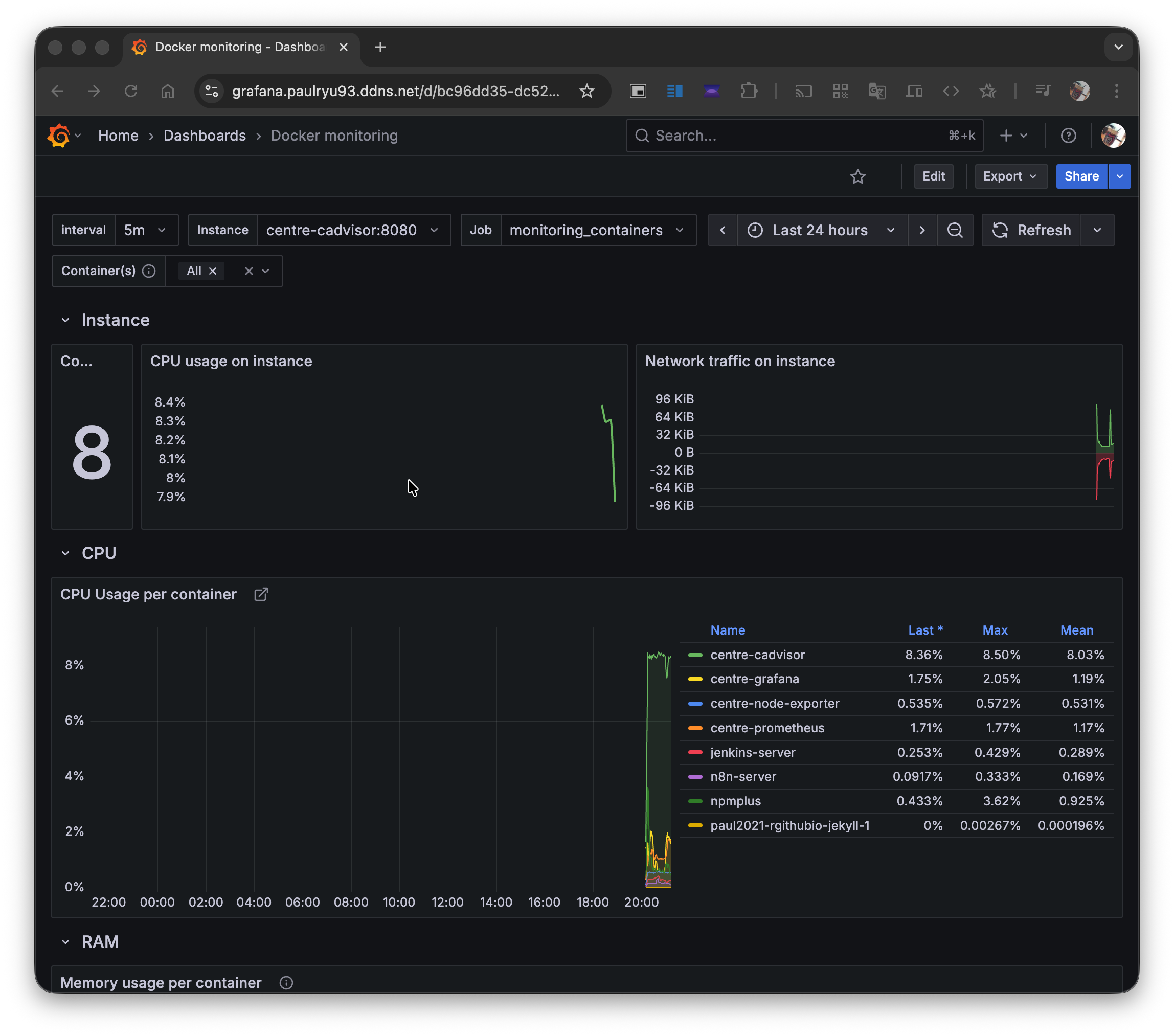
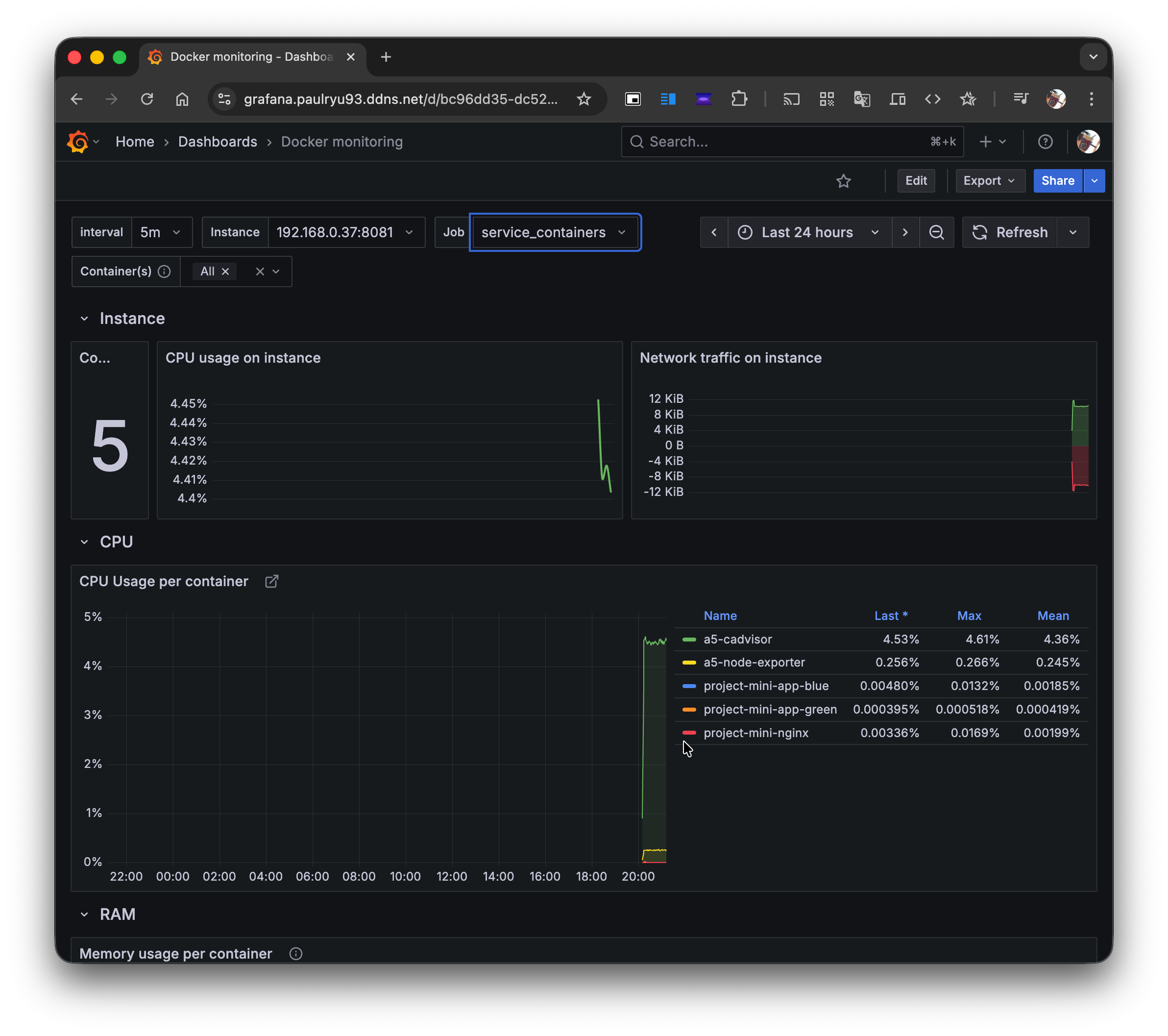
이제 두 서버의 모든 호스트 및 컨테이너 지표를 중앙에서 실시간으로 모니터링할 수 있게 되었다!
아직 알람 기능이라거나, 디테일한 접근은 되지 않았다. 그러나
- G/B 방식의 무중단 배포와 이를 위한 CI/CD Jenkins 파이프라인 구축
- Next.js 기반의 SPA 어플리케이션 서버
- MSA 방식의 NestJS 와 AI를 위한 FastAPI 서버
- 이 모든것을 감시하는 Monitoring의 Grafana + Prometheus 설정 은 앞으로 더욱 흥미 진진한 제대로 된 스케일러블 서비스 구축의 ingnition 이 될 것같다…ㅎ